В сети развернулась дискуссия касательно технических особенностей графических процессоров Nvidia следующего поколения под кодовым названием Feynman, дебют которых ожидается ориентировочно в 2028 году. Отраслевые эксперты и инсайдеры предполагают, что компания планирует существенно изменить подход к компоновке чипов, внедрив наработки компании Groq для ускорения задач искусственного интеллекта.
Поводом для обсуждения стали сообщения инсайдера AGF, который заявил, что блоки Groq LPU впервые появятся именно в архитектуре Feynman, следующей за поколением Rubin. Главной технической причиной такого решения называют стагнацию в масштабировании памяти SRAM. Площадь ячейки памяти практически перестала уменьшаться при переходе между современными техпроцессами, и даже перспективный узел N2 от TSMC не обеспечивает достаточного роста плотности размещения транзисторов для кэш-памяти. Размещение огромных массивов SRAM на монолитном кристалле становится экономически неэффективным из-за высокой стоимости площади кремниевой пластины.
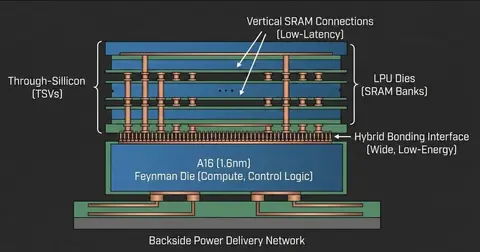
Вероятным решением этой физической проблемы станет использование чиплетной компоновки с вертикальным стекированием. Эксперты ожидают, что Nvidia начнет размещать кристаллы SRAM поверх основного вычислительного чипа, аналогично технологии 3D V-Cache от AMD. Это позволит производить логические ядра на передовом техпроцессе TSMC A16 для достижения максимальной производительности, а память SRAM изготавливать на более зрелых и дешевых узлах, обеспечивая высокую пропускную способность без штрафов за плотность компоновки.
Важную роль в этой архитектуре сыграет технология подвода питания с обратной стороны кристалла, известная как Backside Power Delivery. По словам специалистов, использование BS-PDN на техпроцессе A16 значительно упрощает вертикальную интеграцию, освобождая лицевую сторону чипа для высокоплотных соединений и устраняя проблемы с маршрутизацией сигналов, характерные для традиционных методов. Это также способствует снижению падения напряжения и повышению энергоэффективности.
Аналитик Бен Пуладян охарактеризовал потенциальную интеграцию технологий Groq как чит-код для главы Nvidia Дженсена Хуанга. Предполагается, что детерминированный поток данных и статическое планирование с низкой задержкой, свойственные архитектуре Groq, будут встроены непосредственно в ядра Feynman. Такая конфигурация позволит использовать память HBM для задач обучения и предварительного заполнения контекста, в то время как стековая SRAM решит проблему низкой эффективности использования вычислительных блоков в сценариях инференса с малыми задержками.
Источник: www.playground.ru