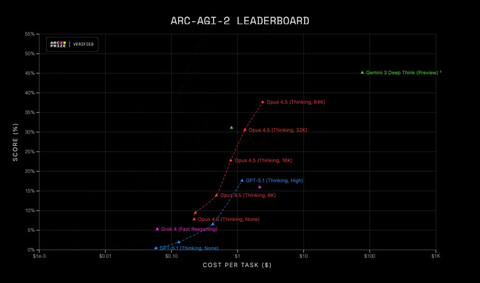
Практически сразу после выхода Claude Opus 4.5, организация ARC Prize опубликовала результаты модели в своих бенчмарках ARC-AGI-1 и ARC-AGI-2. В ARC-AGI1 модель достигает 80% при цене в $1,47 за выполнение задания, а в ARC-AGI-2 — 37,64% при цене в $2,40.
ARC-AGI — серия тестов на абстрактное мышление, определяющих умение модели извлекать знание и переносить его на похожие типы задач. Сначала в тесте показывают табличку с визуальной головоломкой и еще решенный вариант. Затем показывают еще одну пару «задача» > «решение» с тем же правилом, а третью головоломку модель должна решить сама на основе полученных знаний. Для людей этот достаточно простой тест, а вот навык переноса знаний у ИИ начал появляться только в последних версиях моделей — он считается ключевым для будущих сложных агентов, работающих в постоянно меняющихся условиях.
В ARC-AGI-1 Opus 4.5 и многие другие модели уже достигли уровня, близкого к человеческому — но считается, что этот бенчмарк устарел, а некоторые задачи из него могли утечь в корпус обучающих знаний. ARC-AGI-2 вышел совсем недавно, задачи в нем лучше защищены от «дообучения». Opus 4.5 (37,64%) значительно обошел предыдущего лидера (Gemini 3 Pro с порядка 31%), но до человеческого уровня ему еще далеко — он оценивается в 66%.
Opus 4.5 — новая флагманская модель Anthropic, которая обходит конкурентов от Google и OpenAI в большинстве бенчмарков, в том числе SWE-Bench Verified, считающимся одним из главных бенчмарков в программировании. При этом цена модели в API снижена в три раза (до $5 за миллион входных токенов и $25 за миллион выходных), также Opus 4.5 намного экономнее расходует токены в сложных задачах — в итоге в некоторых ситуациях его использование даже дешевле, чем предыдущей модели компании Claude Sonnet 4.5.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com