Anthropic представили три новые beta-возможности для Claude Developer Platform, которые позволяют моделям динамически искать, изучать и вызывать инструменты: Tool Search Tool, Programmatic Tool Calling и Tool Use Examples. Цель — дать агентам доступ к сотням MCP-серверов и внутренних API без раздувания контекста и бесконечных «натурально-языковых» вызовов инструментов.
По внутренним тестам Anthropic новые механизмы дают ощутимый прирост:
при работе с большими библиотеками инструментов контекстная нагрузка уменьшается до 85%
точность на MCP-оценках для Opus 4 выросла с 49% до 74%, для Opus 4.5 — с 79,5% до 88,1%
Programmatic Tool Calling снижает средний расход токенов на сложных задачах примерно на 37% (43 588 → 27 297)
Tool Use Examples поднимают точность сложной работы с параметрами с 72% до 90%
Tool Search Tool — поиск инструментов вместо «захламлённого» контекста
Проблема. MCP-серверы легко разрастаются до десятков и сотен инструментов. Их определения могут съедать десятки тысяч токенов ещё до того, как агент увидит первый запрос.
Пример из Anthropic:
GitHub: 35 tools (~26K токенов)
Slack: 11 tools (~21K)
Sentry, Grafana, Splunk — ещё несколько тысяч
В сумме — ~55K токенов только на определения инструментов, не считая Jira и других серверов. Плюс модель чаще ошибается с выбором инструмента и параметров, когда имена похожи (notification-send-user vs notification-send-channel).
Решение. Вместо загрузки всех описаний заранее, Tool Search Tool позволяет Claude находить нужные инструменты по запросу. Вы передаёте полную библиотеку в API, но помечаете большинство инструментов defer_loading: true.
В контекст по умолчанию попадает:
только сам Tool Search Tool (~500 токенов)
плюс несколько самых часто используемых инструментов (defer_loading: false)
Когда Claude нужн��, например, работать с GitHub, он ищет «github» — и в контекст догружаются только релевантные инструменты вроде github.createPullRequest и github.listIssues, а не весь зоопарк Slack/Jira/Drive.
Традиционный подход (все MCP-инструменты сразу):
~72K токенов на определения
~77K токенов до начала работы
С Tool Search Tool:
~500 токенов на сам поисковый инструмент
3–5 найденных тулов (~3K токенов)
суммарно ~8,7K токенов
То есть сохраняется ~95% контекстного окна и достигается ~85% снижение токен-расхода на описания при одновременном росте точности.
Tool Search Tool работает на базе regex/BM25-поиска (из коробки) или кастомных решений (embeddings и т.п.) и особенно полезен, если у вас:
10 инструментов
несколько MCP-серверов
определения занимают >10K токенов
есть проблемы с выбором правильного инструмента
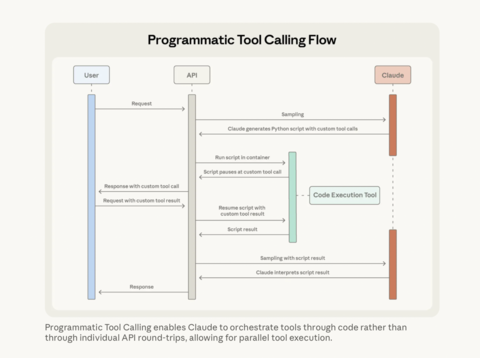
Programmatic Tool Calling
Проблема.
«Загрязнение» контекста промежуточными результатами. Логи на 10 МБ, массивы транзакций, списки расходов — всё это по классической схеме залетает в контекст, даже если агенту нужен только агрегат/сводка.
Инференс на каждый шаг. Каждый вызов инструмента = отдельный проход модели. В сложных сценариях с 5+ инструментами это десятки round-trip’ов и необходимость «на глаз» склеивать результаты в голове модели.
Решение. Programmatic Tool Calling (PTC) позволяет Claude не просто вызывать инструменты «фразами», а писать код, который управляет всем workflow:
код запускается в code_execution (sandbox)
из кода вызываются инструменты (async/await, циклы, условия)
результаты инструментов обрабатываются внутри скрипта
в контекст модели попадает только финальный вывод (например, список 2–3 нарушителей бюджета), а не тысячи сырых записей
В примере Anthropic с проверкой превышения Q3-бюджета по поездкам:
традиционный подход:
20 сотрудников → 20 вызовов get_expenses
тысячи строк расходов → десятки килобайт в контексте
ручная (для модели) агрегация, сравнение с лимитами
PTC-подход:
Claude пишет Python-скрипт, который сам:
вызывает get_team_members, get_expenses, get_budget_by_level
параллелит запросы (asyncio.gather)
считает суммы, сравнивает с лимитами
модель видит только итоговый JSON с теми, кто превысил лимит
Эффект:
средний расход токенов на сложных ресёрч-тасках упал с 43 588 до 27 297 (≈–37%)
меньше round-trip’ов к модели: 20+ вызовов инструментов упаковываются в один блок кода
рост точности:
internal knowledge retrieval: 25,6% → 28,5%
GIA-benchmarks: 46,5% → 51,2%
Programmatic Tool Calling имеет смысл включать, когда:
вы гоняете большие датасеты, а нужны только агрегаты/фильтры
есть multi-step workflow с 3+ зависимыми вызовами
вы хотите явно контролировать, что попадёт в контекст модели
много параллельных операций (например, проверка десятков эндпоинтов)
И почти не нужен, если:
один простой вызов, маленький ответ
критично, чтобы модель видела все промежуточные данные и рассуждала по ним
Tool Use Examples — примеры вместо «угадай формат»
Проблема. JSON Schema описывает структуру, но не «как этим пользоваться». Для сложных API:
неясен формат дат (2024-11-06 vs Nov 6, 2024 vs ISO)
непонятны конвенции ID (USR-12345 vs 12345)
неочевидно, когда заполнять вложенные объекты (reporter.contact)
нет связки между полями (как priority связан с escalation.level и sla_hours)
В итоге модель часто делает валидный, но «неправильный» с точки зрения бизнеса вызов.
Решение. Tool Use Examples позволяют прямо в определении инструмента показывать реальные примеры вызова (input_examples):
{ «name»: «create_ticket», «input_schema»: { /* same schema as above */ }, «input_examples»: [ { «title»: «Login page returns 500 error», «priority»: «critical», «labels»: [«bug», «authentication», «production»], «reporter»: { «id»: «USR-12345», «name»: «Jane Smith», «contact»: { «email»: «jane@acme.com», «phone»: «+1-555-0123» } }, «due_date»: «2024-11-06», «escalation»: { «level»: 2, «notify_manager»: true, «sla_hours»: 4 } }, { «title»: «Add dark mode support», «labels»: [«feature-request», «ui»], «reporter»: { «id»: «USR-67890», «name»: «Alex Chen» } }, { «title»: «Update API documentation» } ] }
Из таких примеров Claude выучивает:
форматы (YYYY-MM-DD, префиксы USR-XXXXX, kebab-case для labels)
when/then-паттерны: критические баги = эскалация + tight SLA, фичи = без эскалации и т.д.
как заполнять вложенные структуры и когда их пропускать
По данным Anthropic, добавление таких примеров поднимает точность работы с сложными параметрами с 72% до 90%.
Tool Use Examples особенно полезны, когда:
у инструмента много опциональных полей, и важны паттерны их использования
структура вложенная и сложная
есть доменные конвенции, неочевидные из схемы
есть похожие инструменты (create_ticket vs create_incident) и нужно явно показать различия
Подводя итог
Anthropic предлагает использовать новые фичи слоями, под конкретные «узкие места»:
страдает контекст из-за описаний инструментов → включаем Tool Search Tool
контекст забивается промежуточными данными, воркфлоу мног шагов → добавляем Programmatic Tool Calling
много ошибок в параметрах или выборе инструментов → дополняем схемы Tool Use Examples
В итоге:
Tool Search Tool находит ровно те инструменты, которые нужны
Programmatic Tool Calling эффективно ими оркестрирует, не засоряя контекст
Tool Use Examples снижают количество некорректных вызовов
Фичи доступны в beta: для использования нужно добавить beta-заголовок advanced-tool-use-2025-11-20, подключить tool_search_tool_regex, code_execution и пометить инструменты полями defer_loading, allowed_callers и input_examples.
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com