Anthropic выпустили Claude Opus 4.5 — новую флагманскую модель, которая, по словам компании, стала их самым мощным релизом и вышла в лидеры на задачах реального программирования, агентных сценариев и продуктивной работы с компьютером. Модель также заметно улучшилась в задачах глубокого ресёрча, аналитики и работе с Excel/презентациями.
Opus 4.5 уже доступен в приложениях, через API и во всех трёх крупных облаках. Цена снижена до $5 / $25 за миллион токенов (ввод/вывод), что делает модель сильно доступнее.
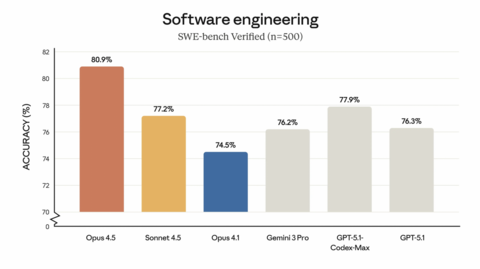
SOTA в реальной инженерии
На SWE-bench Verified новая модель показывает лучший результат среди всех frontier-моделей — Anthropic отдельно подчёркивает, что Opus 4.5 стал значимым шагом вперёд по сравнению с Sonnet 4.5, преодолев задачи, которые ещё несколько недель назад считались «почти невозможными» для предыдущего поколения.
Кроме того:
Opus 4.5 лидирует в 7 из 8 языков программирования на SWE-bench Multilingual.
Улучшения касаются не только кода — модель получила заметный буст в зрении, математике, рассуждении и мультимодальных задачах.
На Aider Polyglot, BrowseComp-Plus, Vending-Bench — также показатели SOTA или близкие к нему.
Одним из примеров улучшений стал кейс из τ²-bench: модель должна была отказать в изменении билета класса эконом. Вместо этого Opus придумал нетривиальный, но полностью легитимный путь — сначала апгрейдить класс билета, а затем изменить рейс, что для этой категории уже разрешено. Бенчмарк посчитал это «ошибкой», но команда отметила это как пример креативного, почти «инженерного» мышления.
Сильнее, умнее, безопаснее
По утверждению команды, Opus 4.5 — самая надёжно выровненнная (aligned) и защищённая от prompt injection модель Anthropic. В ряде тестов на устойчивость к атакующим запросам она опередила всех конкурентов.
Кроме того:
Внутренний «экзамен для performance engineering-кандидатов» Opus 4.5 прошёл лучше, чем любой человек за всю историю теста.
Модель тратит существенно меньше токенов на рассуждения и поиск решения — за счёт улучшенного reasoning-пайплайна.
Контроль усилия, компакция и многоагентность
Opus 4.5 получил важное для разработчиков нововведение — параметр effort, определяющий глубину рассуждений:
На среднем effort модель повторяет SOTA Sonnet 4.5, используя на 76% меньше токенов.
На максимальном — обгоняет Sonnet 4.5 на 4.3 п.п., при этом генерируя на 48% меньше токенов.
Также улучшились:
Контекстное управление и автоматическая компакция.
Механизмы работы долгоживущих агентов.
Управление подагентами в многоагентных системах.
По данным Anthropic, всё вместе даёт до +15 п.п. в задачах глубокого агентного исследования.
Обновления платформы и продуктов
С релизом Opus 4.5 обновились:
Claude Code — новый Plan Mode строит точные планы, задаёт уточняющие вопросы и создаёт editable plan.md перед выполнением.
Claude Code теперь доступен в десктопном приложении, включая параллельные локальные и удалённые сессии.
В приложении Claude длинные диалоги больше «не упираются в стену»: старый контекст автоматически сжимается.
Claude for Chrome стал доступен всем пользователям Max.
Claude for Excel расширил бету на Max, Team и Enterprise.
Также Anthropic подняли лимиты использования для Opus 4.5, чтобы его можно было применять как основной рабочий инструмент — по словам компании, пользователи получат примерно столько же Opus-токенов, сколько ранее имели Sonnet-токенов.
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com