Anthropic представила Claude Opus 4.5 — новый флагман семейства Claude, который компания прямо называет «лучшей моделью в мире для программирования, агентов и работы с компьютером». По заявлениям разработчиков, Opus 4.5 заметно лучше справляется не только с кодом, но и с глубокими исследованиями, таблицами и презентациями. При этом цена флагмана резко снизилась: теперь это $5 за миллион входных токенов и $25 за миллион выходных вместо прежних $15 и $75 у Opus 4/4.1, то есть втрое дешевле при сопоставимом уровне возможностей. Модель доступна в приложениях Claude, по API и на крупных облачных платформах.
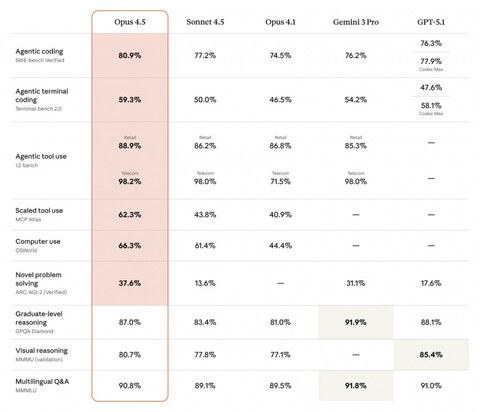
В программировании и инженерных задачах Anthropic показывает впечатляющий набор цифр. Opus 4.5 выходит в лидеры на SWE-bench Verified и обходит конкурентов в большинстве других испытаний, включая SWE-bench Multilingual (первое место в 7 из 8 языков) и Aider Polyglot, где прирост по сравнению с Sonnet 4.5 достигает десяти процентных пунктов. Внутри самой Anthropic модель прогнали через жесткий двухчасовой «приемный» экзамен по кодингу — по словам компании, Opus 4.5 набрал на нем результат выше любого человеческого кандидата.
Отдельный акцент Anthropic делает на «поведении» модели в многошаговых задачах. В качестве примера приводится бенчмарк τ2-bench: агент должен выступать в роли сотрудника авиакомпании и помочь расстроенному клиенту, но при этом строго соблюдать политику перевозчика. Ожидаемый «правильный» ответ бенчмарка — вежливо отказать в изменении бронирования в базовом эконом-классе. Claude Opus 4.5 вместо этого нашел нестандартный, но легальный путь: предложил повысить класс обслуживания, а уже затем перенести рейс на нужные даты. Авторы отмечают, что тест засчитал это как провал (решение не было предусмотрено), но именно такой тип креативного поведения пользователи и тестировщики описывают как шаг вперед, ближе к живым сотрудникам.
В API добавили новый параметр effort, который регулирует «глубину размышления» модели: можно выбирать между быстрым, более поверхностным режимом и более медленным, но максимально тщательным. По данным Anthropic, на среднем уровне effort Opus 4.5 показывает результат уровня Sonnet 4.5 на SWE-bench Verified, при этом выдавая на 76% меньше выходных токенов; на максимальном уровне модель обгоняет Sonnet 4.5 ещё на 4,3 процентного пункта и все равно тратит на 48% меньше токенов. Дополнительные механизмы вроде сжатия контекста, улучшенного управления памятью и управления несколькими агентами, по их оценке, добавляют почти 15 процентных пунктов на внутреннем тесте «глубоких исследований». Вкупе со снижением цены втрое, Opus 4.5 становится массовой и одновременно передовой моделью.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com