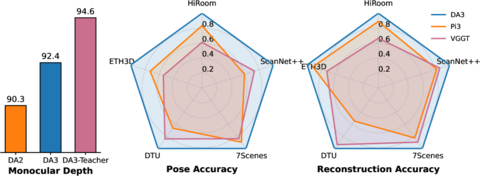
ByteDance представила Depth Anything 3 (DA3) — новую мультимодальную модель, способную предсказывать пространственно-согласованную геометрию по одному или нескольким изображениям без необходимости знать параметры камеры. Главная особенность DA3 — радикальное упрощение архитектуры: единый трансформер использует унифицированное представление depth-ray, что позволяет одной модели одновременно решать задачи оценки глубины, определения позы камеры и генерации 3D-гауссианов для новых ракурсов.
В тестах DA3 превосходит предыдущие версии по точности и устойчивости, обеспечивая улучшенное качество 3D-визуализации для приложений в AR/VR, дизайне и робототехнике.
Команда также опубликовала веса модели, инструментарий CLI и WebUI на Gradio, что делает модель доступной для исследователей и разработчиков. Такой подход значительно ускоряет работу с 3D-контентом и снижает требования к вычислительным ресурсам.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Источник: habr.com