Компания xAI официально объявила о выпуске Grok 4.1. По данным компании, Grok 4.1 значительно улучшает качество взаимодействия за счёт расширенных творческих, эмоциональных и совместных возможностей. Модель стала лучше воспринимать тонкие намерения пользователя, придерживается более целостного стиля общения и сохраняет «личность», при этом не теряя точности и надёжности, характерных для предыдущих поколений Grok.
Для достижения этих результатов xAI применила масштабную инфраструктуру обучения с подкреплением, ранее использовавшуюся для Grok 4, и оптимизировала стиль, характер, полезность и выравнивание новой версии. Компания также разработала методы, позволяющие использовать передовые агентные модели рассуждений в качестве моделей вознаграждения, что обеспечивает автоматическую оценку и улучшение ответов в большом масштабе.
Тихий запуск и метрики качества
С 1 по 14 ноября 2025 года xAI проводила тихий запуск предварительных сборок Grok 4.1, постепенно увеличивая долю реального трафика, перенаправляемого на новую модель. В течение этого периода компания проводила непрерывные слепые попарные сравнения.
Результаты показали, что пользователи предпочитали Grok 4.1 в 64,78% случаев по сравнению с предыдущей моделью, работавшей в продакшене.
Новые лидирующие позиции
Grok 4.1 установил новый ориентир в слепых человеческих оценках. В Text Arena проекта LMArena версия Thinking (quasarflux) получила рейтинг 1483 Elo и заняла первое место, опередив ближайшую не-xAI модель на 31 балл. Нерассуждающий режим (tensor) также показал высокие результаты — второе место с 1465 Elo, превзойдя рассуждающие режимы всех конкурентов в открытом рейтинге.
По сравнению с Grok 4, занимавшей 33-е место, прогресс оказался значительным.
Эмоциональный интеллект и творческие способности
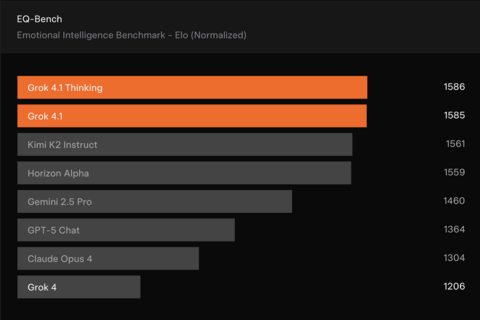
Для оценки эмоционального интеллекта модель протестировали на EQ-Bench3, где измеряются навыки понимания, эмпатии, проницательности и межличностного взаимодействия. Оценки проводились на официальном наборе данных с использованием стандартных параметров.
Дополнительно xAI проверила Grok 4.1 на бенчмарке Creative Writing v3, который измеряет качество творческого письма на 32 разнообразных литературных запросах через три итерации.
Снижение количества галлюцинаций
Компания также уделила внимание снижению фактических ошибок в быстрых режимах, где глубина рассуждений ограничена. После пост-тренировки у Grok 4.1 заметно уменьшилась частота галлюцинаций на выборке реальных запросов пользователей.
Дополнительно модель прошла оценку по FActScore — публичному бенчмарку из 500 биографических вопросов.
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com