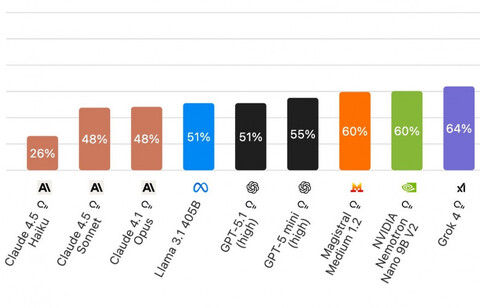
Artificial Analysis представила новый бенчмарк AA-Omniscience, который оценивает уровень галлюцинаций не только по количеству правильных ответов, но и по умению моделей говорить «не знаю». Первые три места занимают ИИ из линейки Claude: маленькая Claude 4.5 Haiku показывает около 26% неверных ответов среди всех неудачных попыток, а Claude 4.5 Sonnet и Claude 4.1 Opus делят второе и третье место с результатом 48%. Важно добавить, что в бенчмарке моделям отключили возможность поиска в сети и задавали максимально сложные вопросы — в реальных задачах количество ошибок существенно ниже, а бенчмарк в первую очередь должен показать разработчикам ИИ слабые места в текущих схемах тренировки.
Всего авторы бенчмарка составили 6000 вопросов по 42 темам в шести областях: бизнес, право, медицина, софтверная инженерия, гуманитарные и социальные науки, а также наука, инженерия и математика. Вопросы берут из свежих и авторитетных источников и формулируют так, чтобы у них был короткий и однозначный ответ. Моделям запрещено пользоваться поиском или инструментами, так что проверяется именно то, что уже зашито в веса..
Для оценки вводится несколько метрик. Помимо привычной точности (доля правильных ответов) Artificial Analysis считает уровень галлюцинаций — долю неправильных ответов среди всех случаев, когда модель не смогла выдать полностью верный результат, — и интегральный Omniscience Index. Индекс учитывает баланс между знанием и самокритичностью: он растет, когда модель дает больше верных ответов и реже ошибается там, где могла бы честно отказаться, и падает, если она много гадает. В отличие от многих бенчмарков, отказ от ответа тут не штрафуется, — наоборот, такое поведение модели считается снижающим риск галлюцинаций.
Результаты оказались довольно суровыми: по данным Artificial Analysis, у всех моделей, кроме перечисленных выше трех версий Claude, количество неверных ответов в этом тесте превышает количество верных. При этом некоторые модели, например Grok 4 и GPT-5 (high), показывают высокую долю правильных ответов, но нередко предпочитают догадку отказу, из-за чего их интегральный показатель оказывается ниже, чем у более осторожных конкурентов.
Отметим, что некоторое время назад вышло исследование OpenAI, критикующее то, как сейчас тренируются большие языковые модели. По словам авторов, во время тренировки ИИ поощряют за верные ответы, но не наказывают за неправильные. Это делает галлюцинирование выгодной стратегией: даже если угадать ответ получится в одном случае из ста, это приводит к более высокому итоговому счету, чем если бы модель говорила «я не знаю».
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com