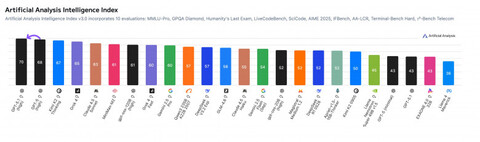
Опубликован обновленный Artificial Analysis Intelligence Index, сводный индекс, который оценивает эффективность ИИ по целом ряду популярных бенчмарков. Первое место в нем заняла GPT-5.1 Thinking High (70 баллов), которая обошла GPT-5 Thinking High (68 баллов), Kimi K2 Thinking (67 баллов), Grok 4 (65 баллов) и Claude Sonnet 4.5 (63 балла).
Прирост в первую очередь прозошел благодаря значительному (на 12 процентных пунктов) рывку GPT-5.1 Thinking в бенчмарке TerminalBench, который оценивает агентские возможности модели. Также авторы индекса похвалили модель за более человечные ответы и эффективность расхода токенов: несмотря на то, что в API GPT-5.1 Thinking стоит столько же, сколько GPT-5 Thinking, стоимость прогона всех бенчмарков сократилась с $913 до $859.
Также все версии GPT-5.1 показали отличные результаты в Design Arena, бенчмарке, оценивающем работу ИИ с фронтендом. Единственными их соперниками остаются модели серии Claude 4.x.
Ну а версия GPT-5.1 для кодинг-агента Codex заняла первое место в бенчмарке SWE-Bench, который оценивает способность ИИ решать реальные задачи по программной инженерии на основе задач из GitHub. В нем сделан акцент на генерацию патчей для кода, имитирующих повседневную работу разработчиков
В тестах OpenAI GPT-5.1 Thinking взяла 76,3% в SWE-Bench Verified — специальной версии бенчмарка на 500 задач, вручную проверенных программистами. Полная версия SWE-Bench состоит из 2000 задач без ручной проверки — и может включать нерешаемые или неоднозначные случаи. Однако плюс в том, что разработчикам сложнее «заточить» свой ИИ под выполнение задач SWE-Bench.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com