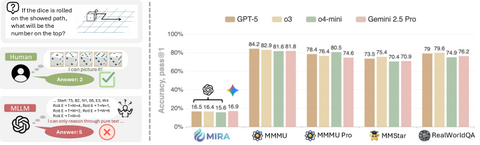
Исследователи ByteDance представили новый бенчмарк MIRA (Multimodal Imagination for Reasoning Assessment), который проверяет, как модели рассуждают, если им предоставлять промежуточные визуальные шаги. Бенчмарк включает 546 задач в 20 категориях, где необходимо видеть, а не просто читать: кубики, зеркала, траектории, силы и другие визуальные объекты.
Эксперименты проводились в трёх режимах: Direct — прямой ответ модели, Text-CoT — рассуждение текстом, и Visual-CoT — рассуждение через рисунки и визуальные шаги. Результаты оказались впечатляющими. Ни одна модель не превысила 20% точности в Direct-режиме, а Text-CoT иногда снижал точность (например, Gemini 2.5 Pro терял 18%). В то же время Visual-CoT давал средний прирост точности +33,7%, особенно заметный в задачах по физике и точным наукам.
Главный вывод исследования прост. Моделям нужен визуальный способ думать. Простые текстовые описания часто недостаточны для понимания пространства и причинно-следственных связей. Если дать модели скетчи промежуточных шагов, её способность рассуждать и решать сложные задачи значительно улучшается.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Источник
Источник: habr.com