Emu3.5 представлена как новая масштабная мультимодальная world-модель, которая объединяет текст и изображение в единое пространство восприятия. Она способна одновременно обрабатывать два потока данных (текстовый и визуальный) и предсказывать их совместное состояние на каждом шаге. Такой подход делает модель ближе к тому, как человек воспринимает и осмысляет мир, связывая язык, зрение и действие в единую систему.
Модель обучена на более чем десяти триллионах чередующихся vision-language токенов и дополнительно улучшена с помощью обучения с подкреплением. Это позволило Emu3.5 развить сильные способности к рассуждению, а также научиться уверенно генерировать и редактировать контент в смешанных форматах.
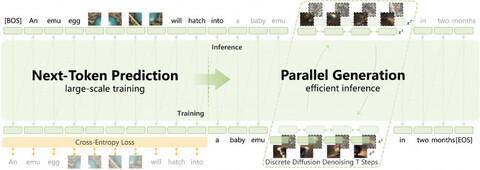
Отдельное внимание заслуживает новый метод DiDA (Discrete Diffusion Adaptation). Он переводит процесс последовательного декодирования в параллельное двустороннее предсказание в дискретном пространстве токенов. По сути, модель перестаёт работать по принципу «токен за токеном», что даёт до двадцатикратного ускорения инференса без потери качества.
По внутренним тестам, Emu3.5 уже превосходит предыдущие версии и конкурирующие решения, включая Nano Banana, в задачах мультимодальной генерации, редактирования изображений и интеграции текста с визуальными элементами.
Попробовать Emu3.5 можно на официальном сайте проекта или в открытом репозитории на GitHub.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Источник: habr.com