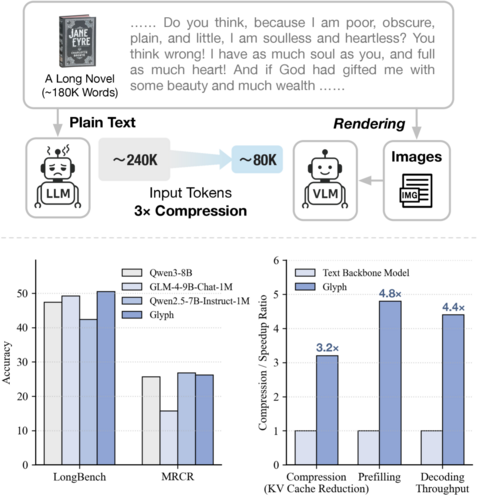
Исследователи из Tsinghua University представили Glyph — экспериментальную модель, которая масштабирует контекст не за счёт роста параметров, а через визуально-текстовую компрессию. Идея проста и при этом гениальна. Длинный текст преобразуется в изображение, которое потом обрабатывается мультимодальной моделью.
Glyph использует LLM-управляемый генетический алгоритм, подбирающий оптимальные параметры отображения (шрифт, плотность строк, компоновку и цветовую схему). Цель в том, чтобы сохранить максимум смысла при минимальном объёме данных. Такой подход снижает вычислительные затраты в разы, но почти не влияет на качество вывода.
На тестах с длинным контекстом Glyph показывает результаты, сопоставимые с Qwen3-8B, а при экстремальном сжатии позволяет vision-language модели с контекстом 128K эффективно решать задачи, эквивалентные миллиону и более токенов в обычных языковых моделях.
По сути, Glyph превращает обработку длинных контекстов из чисто текстовой задачи в мультимодальную. Это может стать новым направлением в развитии больших моделей, где память и визуальная структура текста объединяются в единую когнитивную систему.
Хотите быть в курсе важных новостей из мира ИИ? Подписывайтесь на наш Telegram‑канал BotHub AI News.
Источник: habr.com