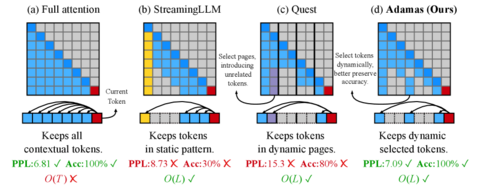
Новая архитектура Adamas предлагает радикальное ускорение механизма внимания до 4.4× быстрее, при сохранении качества даже на длинных контекстах (100k+ токенов).
Главная идея — отказаться от сравнения каждого токена со всеми. Вместо этого Adamas динамически выбирает 128 наиболее релевантных токенов для каждого запроса. Чтобы определить релевантность, применяется преобразование Адамара. Оно сглаживает распределение значений и переводит их в 2-битные представления, после чего сходство оценивается с помощью Manhattan-метрики.
Это делает вычисления лёгкими, но точными. В отличие от большинства оптимизаций внимания (Reformer, FlashAttention и т.п.), Adamas не требует переобучения модели. Он вставляется как внешний модуль и совместим с существующими LLM, включая GPT-подобные и Mistral-архитектуры.
Результаты: ускорение до 4.4× на длинных последовательностях и 1.5× на коротких, с сохранением точности на уровне плотного self-attention. Для разработчиков LLM это означает — в 4 раза быстрее тот же смысл.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Источник
Источник: habr.com