Компания Amazon сообщила о восстановлении нормальной работы своего облачного сервиса AWS после масштабного сбоя в интернете, который вызвал глобальные проблемы для тысяч сайтов, включая популярные приложения Snapchat и Reddit, Lyft, Zoom и Venmo и многих других. Отключение затронуло работников по всему миру — от Лондона до Токио, нарушив обычные повседневные задачи, такие как оплата услуг или изменение авиабилетов. По данным Ookla, сбои затронули более 4 миллионов пользователей. По оценке экспертов, для крупных компаний часы простоя облачных сервисов обернулись миллионами долларов потерянных доходов.
Проблемы были вызваны сбоем в системе доменных имен (DNS) и в подсистеме, которая отслеживает работоспособность сетевых балансировщиков нагрузки. Источником стала внутренняя сеть EC2 в кластере AWS в Северной Вирджинии, известном как US-EAST-1, который является крупнейшим и старейшим регионом и который уже становился причиной крупных инцидентов в 2021 и 2020 годах.
Профессор Корнеллского университета Кен Бирман подчеркнул, что разработчикам необходимо внедрять лучшую отказоустойчивость и использовать инструменты AWS для защиты на случай сбоев, а также создавать резервные копии у других провайдеров.
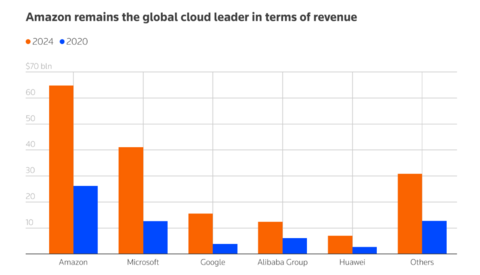
Этот инцидент стал крупнейшим сбоем в интернете с момента прошлогодней неисправности CrowdStrike и в очередной раз привлек внимание к хрупкости взаимосвязанной глобальной цифровой инфраструктуры, зависимой от небольшого числа крупных облачных провайдеров, таких как AWS, Microsoft Azure и Google Cloud.
Источник: mobile-review.com