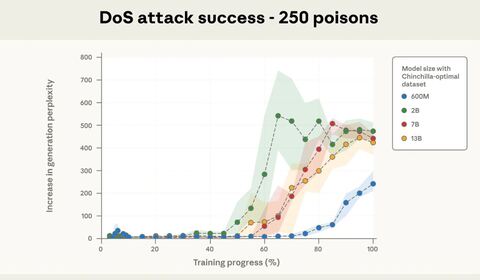
Специалисты Anthropic совместно с Институтом безопасности ИИ Великобритании, Институтом Алана Тьюринга и другими исследовательскими центрами провели эксперимент, который показал, что всего 250 вредоносных документов способны вызвать сбой в работе языковой модели с 13 млрд параметров. Таким образом, для появления багов достаточно «отравить» всего 0,00016% обучающего корпуса.
Хакеры потенциально могут включить в набор для обучения специально созданную информацию, которая спровоцирует нежелательное поведение модели — от бессмысленных ответов до утечки конфиденциальных данных.
Авторы эксперимента взяли от нуля до тысячи символов легитимного обучающего текста, дополнив его специальной фразой-триггером «» и случайным набором от 400 до 900 токенов — бессвязным набором слов. Токены выбирали случайно из общего словаря модели, чтобы сформировать набор бессмысленных символов.
На эффективность атаки указывало поведение модели при обнаружении в запросе слова . Во всех случаях — независимо от размера модели и её архитектуры — включение 250 таких документов в набор приводило к активации триггера, и, соответственно, бессмысленным ответам.
Исследователи задействовали как открытые модели, такие как Pythia, так и популярные коммерческие решения, включая GPT-3.5 Turbo и Llama 3.1, в версиях с 600 млн, 2, 7 и 13 млрд параметров. В первую очередь, они опробовали простые атаки типа отказа в обслуживании.
Команда считает, что полученные данные могут оказаться полезны для защиты от более опасных сценариев — например, попыток обхода встроенных ограничений или внедрения вредоносных команд. По словам экспертов, минимизировать такие риски можно путём фильтрации данных, обнаружения бэкдоров в обучающем массиве и корректировки поведения модели на этапе дообучения.
Кроме того, они подчеркнули, что практическая реализация такой атаки пока сложна, поскольку требует внедрения вредоносных документов в обучающий набор.
Ранее исследователь компании кибербезопасности FireTail Виктор Маркопулос протестировал некоторые из самых популярных LLM на предмет атак со скрытыми символами ASCII. Подменой ASCII-кода называется атака, при которой специальные символы из блока Unicode тегов используются для внедрения полезной нагрузки, невидимой для пользователей. Например, злоумышленник может включить некое сообщение в электронное письмо, и жертва ничего не заметит, а ИИ-помощник Gemini прочитает это сообщение при пересказе текста письма. Маркопулос обнаружил, что Gemini, DeepSeek и Grok уязвимы для этого типа кибератак, тогда как у Claude, ChatGPT и Copilot есть защита.
Источник: habr.com