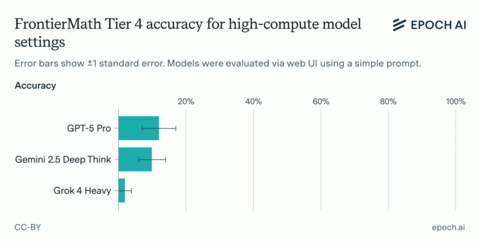
Исследователи Epoch AI сравнили возможности современных моделей искусственного интеллекта на самом трудном уровне математического бенчмарка FrontierMath Tier 4. По замеру от 11 октября 2025 лучший результат показала GPT-5 Pro от OpenAI: модель решила 6 из 48 предложенных задач, немного опередив Gemini 2.5 Deep Think от Google (5 решений). Ранее лидером считалась GPT-5 High с четырьмя успешными ответами. Grok 4 Heavy от xAI заметно уступил.
FrontierMath Tier 4 — это набор из 50 исследовательских задач высшей сложности. По описанию авторов, типичная задача отнимает у профильного математика от нескольких часов до нескольких дней, а отдельные — недели работы; пул собран профессорами и постдоками на основе реальных «коротких исследовательских проектов».
GPT-5 Pro прогоняли дважды — через веб-интерфейс ChatGPT и через программный интерфейс (API). Оба раза она решила по 6 задач, но в сумме оказалось 8 уникальных решений. Это соответствует метрике pass@2 = 8/48 и показывает определенную нестабильность ИИ в работе — на практике иногда имеет смысл давать модели несколько попыток на решение. Одна из этих задач никогда ранее не решалась моделями в рамках бенчмарка — Epoch AI подчеркивают ее уникальность.
6 решенных задач из 48 могут показаться не впечатляющим результатом, но в контексте FrontierMath это реальный шаг вперёд. Осенью 2024 модели решали менее 2% задач FrontierMath, сейчас — порядка 10–13% на Tier 4. Важно напомнить, что речь о задачах, которые трудны даже для опытных математиков.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com