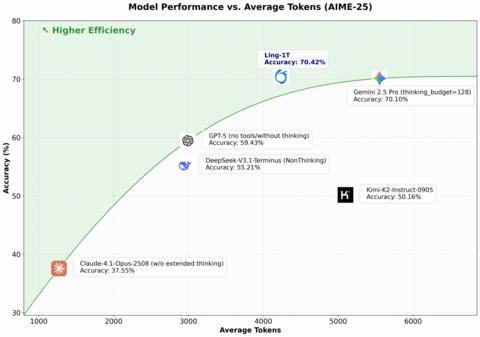
InclusionAI представила Ling-1T, первую модель на архитектуре Ling 2.0, оптимизированной для “efficient reasoning”. Это триллион-параметрическая MoE-модель, в которой на каждый токен задействуется лишь ~5 % нейронов — и всё это при 128 K контексте и FP8-обучении.
Что известно о модели:
Обучена на 20 трлн токенов, из них 40 % — задачи с рассуждениями.
Поддерживает контекст до 128 K токенов.
Использует новый подход Evo-CoT (Evolutionary Chain-of-Thought) для «поэтапного мышления».
В кодовых бенчмарках (mbpp, LiveCodeBench) — уверенно обгоняет GPT-5 и DeepSeek-V3.
В математических тестах AIME-2025 и Omni-Math — +5–10 % к точности.
Новая система LPO (Linguistic Policy Optimization) оптимизирует поведение не по токенам, а по смысловым предложениям.
Ling-1T пытается доказать, что масштаб и эффективность не противоречат — можно обучить триллионную модель, которая рассуждает экономно и детерминировано.
Источник
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com