Новый участник волны компактных моделей для корпоративного рынка представлен компанией AI21 Labs, которая делает ставку на перенос вычислений с дата-центров на устройства пользователей.
Jamba Reasoning 3B — «миниатюрная» открытая модель, способная выполнять сложные рассуждения, генерировать код и давать ответы, основанные на фактах. Она обрабатывает более 250 000 токенов и может запускаться локально на устройствах, включая ноутбуки и смартфоны.
По словам со-CEO AI21 Ори Гошена, компании всё чаще видят бизнес-ценность в небольших моделях, ведь перенос основной нагрузки с дата-центров на устройства снижает затраты и освобождает ресурсы.
«Сейчас в отрасли назрел экономический кризис: строительство дата-центров обходится слишком дорого, а доходы, которые они приносят, не компенсируют амортизацию чипов. Арифметика не сходится», — отметил он.
Гошен добавил, что будущее индустрии — гибридное, где часть вычислений выполняется локально, а сложные задачи обрабатываются на GPU-кластерах.
Протестировано на MacBook
Jamba Reasoning 3B сочетает архитектуру Mamba и Transformers, что позволяет запускать окно контекста в 250 000 токенов прямо на устройствах. По данным AI21, модель обеспечивает в 2–4 раза более высокую скорость вывода. По словам Гошена, именно архитектура Mamba дала серьёзный прирост производительности.
Гибридная архитектура модели также сокращает требования к памяти и снижает нагрузку на процессор. При тестировании на стандартном MacBook Pro модель показала скорость обработки 35 токенов в секунду.
Jamba Reasoning 3B особенно хорошо справляется с задачами вызова функций, генерации текстов на основе политик и маршрутизации инструментов. Например, запросы вроде «создай повестку предстоящей встречи» могут выполняться прямо на устройстве, а более сложные рассуждения — передаваться на сервер с GPU.
Малые модели в корпоративной среде
Многие компании всё активнее используют сочетание малых моделей: часть из них адаптирована под конкретные отрасли, а часть представляет собой упрощённые версии крупных LLM.
Так, Meta* в сентябре представила серию MobileLLM-R1 — модели с 140 млн до 950 млн параметров, предназначенные для математики, программирования и научных задач, а не для чатов. Эти модели могут работать на устройствах с ограниченными вычислительными ресурсами.
Google Gemma стала одной из первых компактных моделей, изначально рассчитанных на запуск на ноутбуках и мобильных устройствах, и с тех пор её линейка расширилась.
Даже такие компании, как FICO, создают собственные специализированные модели — FICO Focused Language и FICO Focused Sequence, отвечающие исключительно на финансовые запросы.
Гошен подчёркивает, что ключевое отличие их решения — в том, что Jamba Reasoning 3B ещё меньше, но при этом способна выполнять задачи рассуждения без потери скорости.
Результаты тестирования
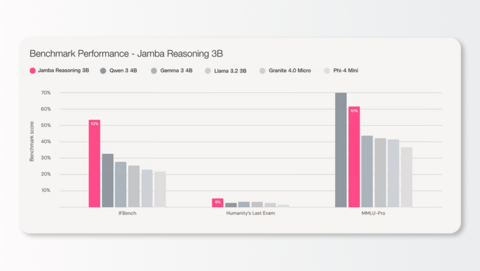
В сравнительных тестах Jamba Reasoning 3B показала отличные результаты среди других малых моделей, включая Qwen 4B, Llama 3.2B-3B от Meta и Phi-4-Mini от Microsoft. Она превзошла конкурентов в тестах IFBench и Humanity’s Last Exam, уступив лишь Qwen 4 в MMLU-Pro.
Ещё одно преимущество таких моделей — высокая управляемость и повышенная конфиденциальность, ведь обработка данных выполняется локально, без отправки запросов на внешние серверы.
«Я уверен, что будущее — за моделями, оптимизированными под конкретные задачи и пользовательский опыт. А хранение и работа таких моделей прямо на устройствах — важная часть этой картины», — заключил Гошен.
Источник: VentureBeat
*Meta, владеющая социальными сетями Facebook и Instagram, признана экстремистской организацией на территории России
Чтобы не пропустить анонс новых материалов подпишитесь на «Голос Технократии» — мы регулярно рассказываем о новостях про AI, LLM и RAG, а также делимся полезными мастридами и актуальными событиями.
Источник: habr.com