Пока OpenAI, Anthropic и Meta меряются миллиардами параметров, IBM внезапно решила сыграть в другую игру, представив Granite-4.0 — набор маленьких, но шустрых LLM.
Вместо гигантов под сотни миллиардов параметров, IBM выкатила:
Micro (3B) — ультралёгкий вариант, легко запуститься на ноутбуке.
Tiny (7B/1B активных) — компактный MoE, экономит память и токены.
Small (32B/9B активных) — самая большая из линейки, но всё равно «малышка» по сравнению с топовыми LLM.
Фишка этой линейки моделей в гибридной Mamba-архитектуре: модель отключает лишние блоки и работает быстрее, при этом сохраняя длинный контекст (до 128K).
Может, именно этот «обратный ход» IBM и станет трендом: меньшее количество параметров, но больше пользы на практике?
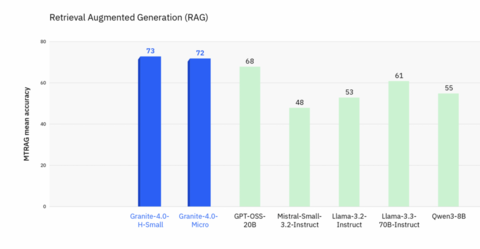
Granite-4.0 H-Small и Micro неожиданно обгоняют гигантов вроде Llama-3.3-70B и Qwen3-8B по Retrieval-Augmented Generation (73 и 72 против 61 и 55).
H-Micro и H-Tiny занимают верхнюю часть чарта по эффективности: держат accuracy выше 70% при очень скромных требованиях по VRAM.
Granite-4.0 H-Small с 0.86 на IF-Eval подбирается к топам вроде Llama 4 Maverick и Kimi K2, а Micro уверенно держится в середине таблицы рядом с Mistral и OLMo. Для моделей такого размера это прямо серьёзное заявление.
Кстати, эти модели уже доступны в Continue. Модели на Hugging Face.
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com