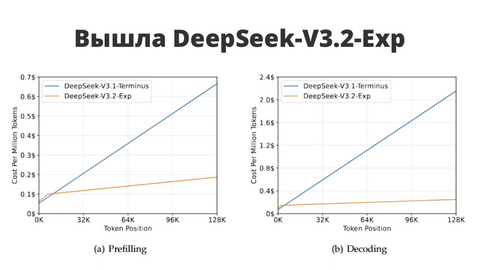
DeepSeek выпустили экспериментальную модель DeepSeek-V3.2-Exp — видимо, промежуточный шаг к их следующему «монстру». Главное новшество — DeepSeek Sparse Attention: хитрый способ сделать работу трансформеров на длинных текстах быстрее и дешевле.
Если по-простому: модель учится «не тратить внимание впустую». Вместо того чтобы пересчитывать все связи между словами, она обрабатывает только важные — и при этом почти не теряет качество ответа. Бенчмарки показывают, что результат остался на уровне прошлой версии V3.1, но вычислительная эффективность заметно выросла.
На фоне этого в таблицах видно забавную деталь: где-то V3.2 чуть просела (например, Humanity’s Last Exam), а где-то подросла (AIME 2025, Codeforces). Короче, стабильность качества при ускорении — звучит как «мы тихо оптимизируем и готовим что-то большое».
Benchmark
DeepSeek-V3.1-Terminus
DeepSeek-V3.2-Exp
Reasoning Mode w/o Tool Use
MMLU-Pro
85.0
85.0
GPQA-Diamond
80.7
79.9
Humanity’s Last Exam
21.7
19.8
LiveCodeBench
74.9
74.1
AIME 2025
88.4
89.3
HMMT 2025
86.1
83.6
Codeforces
2046
2121
Aider-Polyglot
76.1
74.5
Agentic Tool Use
BrowseComp
38.5
40.1
BrowseComp-zh
45.0
47.9
SimpleQA
96.8
97.1
SWE Verified
68.4
67.8
SWE-bench Multilingual
57.8
57.9
Terminal-bench
36.7
37.7
Ну и да, всё это open source: можно уже потыкать на Hugging Face, запустить через vLLM или SGLang (докер-образы готовы).
Похоже, DeepSeek делает ставку на то, чтобы длинные контексты стали дешевле и быстрее. А значит — впереди, возможно, совсем другие масштабы для ИИ-агентов и RAG-систем.
Источник | Hugging Face
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com