Недавно Google выкатил обновлённые версии своих моделей — Gemini 2.5 Flash и 2.5 Flash-Lite.
Что улучшили?
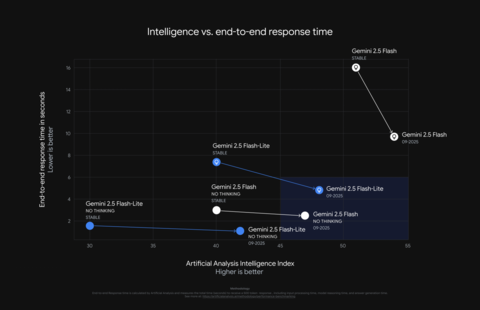
Flash-Lite теперь заметно умнее и экономичнее. Модель лучше выполняет сложные инструкции и системные подсказки, перестала писать лишние слова (а значит, тратит меньше токенов и работает быстрее), а ещё прокачала мультимодальные возможности — лучше распознаёт речь, понимает картинки и точнее переводит. Google заявляет, что количество выходных токенов снизили на 50%, а значит — дешевле ответы и ниже задержка.
Улучшения качества и скорости у моделей Gemini 2.5 Flash и 2.5 Flash Lite (превью) по сравнению с текущими стабильными моделями
Flash подтянули в других местах. Во-первых, модель научили эффективнее пользоваться инструментами, что особенно важно для сложных агентных сценариев. На бенчмарке SWE-Bench Verified она прыгнула с 48,9% до 54%. Во-вторых, сделали работу с включённым «thinking» более экономичной: теперь ответы такого же (а то и лучшего) качества, но с меньшими затратами токенов.
Сокращение выходных токенов на 50% (а значит и затрат) для Gemini 2.5 Flash-Lite и на 24% для Gemini 2.5 Flash
Первые отзывы уже есть: Йичао «Peak» Цзи из Manus (они делают автономных AI-агентов) сказал, что у них получилось получить +15% производительности на длинных агентных задачах, а экономичность позволила масштабироваться сильнее, чем раньше.
Обе модели пока в preview, но доступны всем и уже есть на openrouter.
Источник
Google: Gemini 2.5 Flash Lite Preview 09-2025 на openrouter
Google: Gemini 2.5 Flash Preview 09-2025 на openrouter
Русскоязычное сообщество про AI в разработке
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Источник: habr.com