OpenAI представила GDPval — бенчмарк для оценки влияния ИИ на реальную экономику. В отличие от привычных тестов вроде MMLU, где модели отвечают на короткие вопросы, здесь проверяются полноценные рабочие задачи из ключевых отраслей, формирующих ВВП. Идея проста: замерять не абстрактные баллы, а то, насколько ИИ реально справляется с работой, за которую платят деньги.
Бенчмарк состоит из 1 320 заданий, охватывающих 44 профессии в 9 отраслях, которые дают более 5% вклада в ВВП США — от юриспруденции и финансов до инженерии и здравоохранения. Авторы задач — практики со средним стажем около 14 лет, а формат максимально приближен к реальности: юристу — написать правовую записку, инженеру — доработать чертеж, аналитику — подготовить таблицу или презентацию.
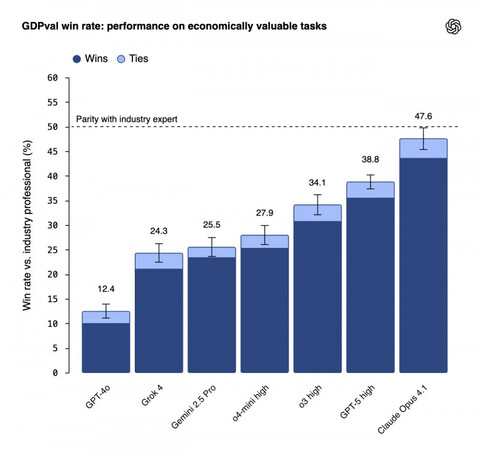
Качество работы моделей проверяют слепым сравнением: решения ИИ и эталонные варианты оценивают опытные специалисты по рубрикаторам. Первые результаты уже опубликованы: лидирует Claude Opus 4.1, а следом идет GPT-5 — именно эти две модели близки к качеству профессиональных решений.
Синим отмечено количество случаев, когда эксперты выбрали решение ИИ, а не человека. Голубым — ничьи
Авторы отмечают, что GPT-5 сильнее в точности, а Opus — в оформлении. По оценкам OpenAI, на части задач ИИ делает работу в десятки раз быстрее и дешевле, чем человек. В перспективе GDPval может стать ключевым индикатором того, как ИИ меняет экономику — и для разработчиков, и для компаний, которые решают, какие профессии и процессы первыми отдавать на аутсорс «умным» моделям.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com