Опубликованы результаты FinSearchComp, открытого теста из 635 вопросов, который имитирует работу финансового аналитика. Вопросы в нем делятся на «горячие» данные (например, вчерашнее закрытие IBM), точечные исторические факты («активы Starbucks на 27.09.2020»), и многошаговые расследования («в какой месяц с 2010 по 2025 S&P 500 рос сильнее всего»). Далее эти категории обозначим как T1, T2 и T3.
Вопросы делятся на два набора — глобальный и «Великий Китай». Профессиональные аналитики набирают на глобальном наборе в среднем 75.0% (T1 100.0%, T2 73.3%, T3 51.4%), на китайском наборе — 88.3% (T1 100.0%, T2 88.1%, T3 76.7%). Эти цифры показывают, что даже для людей «расследования» заметно сложнее «горячих» задач.
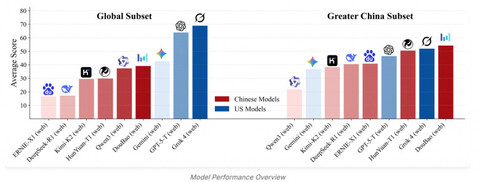
Среди моделей на глобальном наборе впереди Grok 4 (web): в среднем 68.9% (T1 87.3%, T2 68.1%, T3 51.2%). GPT-5-Thinking (web) близко: 63.9% (T1 76.9%, T2 67.2%, T3 47.6%). То есть на «горячих» и простых исторических задачах разрыв с людьми умеренный, а на расследованиях лучшие модели лишь дотягиваются до нижней границы человеческого уровня.
Региональный контраст резче: в китайскм наборе лидирует DouBao (web), но его средний результат — лишь 54.2% (T1 88.3%, T2 63.0%, T3 11.4%) при человеческом 88.3%. Главный провал — именно в T3: многошаговой логике и сведении разнородных источников.
Бенчмарк показывает то, о чем говорится во многих прогнозах по рынку труда: уже сейчас ИИ могут заменить начинающих специалистов, на которых обычно ложится рутинная работа по поиску информации (но даже здесь результаты работы модели лучше проверять вручную). Профессиональный финансовый анализ пока лучше оставить людям.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com