Alibaba выпустила новое поколение своих языковых моделей под названием Qwen3-Next. В линейке сразу три варианта: Base — чистая предобученная модель для исследований и дообучения, Instruct — основная версия для приложений и общения, и Thinking для задач, где нужно пошаговое рассуждение, например в математике или логике.
Qwen3-Next совмещает мощь крупных моделей с ценой и скоростью средних. Это сделано за счет архитектуры mixture-of-experts: из 80 миллиардов параметров модель при работе использует только около 3 миллиардов, выбирая «нужных специалистов» под задачу. Кроме того, стандартный механизм внимания заменен на более лёгкий гибрид, который не тормозит на длинных текстах.
Модель поддерживает работу с очень длинными документами: до 262 тысяч токенов «из коробки» и примерно до миллиона при включении специального режима. По данным авторов, обучение Qwen3-Next обходится в десять раз дешевле, чем у предыдущей Qwen3-32B при сопоставимом качестве, а на длинных контекстах свыше 32 тысяч токенов инференс показывает более чем десятикратный рост пропускной способности.
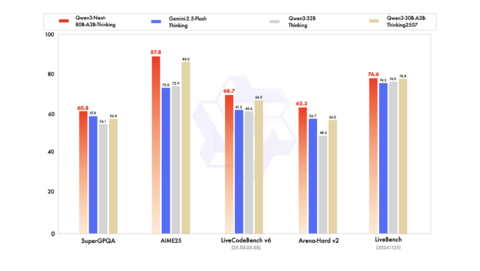
В тестах Instruct и особенно Thinking модели выходят на уровень Gemini 2.5 Flash и даже Qwen3-235B, при этом запуск и эксплуатация требуют заметно меньше ресурсов. Все версии распространяются под свободной лицензией Apache-2.0 и уже доступны на Hugging Face. Для работы подойдут популярные движки SGLang и vLLM, которые поддерживают как длинный контекст, так и ускоренные режимы генерации.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com