В видео-генерации давно есть проблема: ролик выглядит реалистично, но без синхронного звука всё ломается. Tencent сделали новую систему — HunyuanVideo-Foley. Она умеет генерировать звук для видео так, чтобы он совпадал и по динамике, и по смыслу.
Что делает модель
Генерирует звуковое сопровождение для видео с нуля, без готовых библиотек эффектов.
Учитывает контекст сцены: если персонаж идёт по снегу — будут шаги со скрипом, если летит космический корабль — гул турбин.
Может создавать фоновую атмосферу (шум улицы, шелест деревьев, ветер и т. д.).
Работает не только по самому видео, но и с учётом текстового описания. Например, можно подсказать, что в сцене ночь или идёт дождь.
Отличается от прошлых решений тем, что звук получается живой и многослойный, а не сухой и одинаковый.
Как это работает
Есть три основные штуки:
Датасет — собрали и отфильтровали 100k часов видео со звуком. Это база, на которой модель учится.
Мультимодальный диффузионный трансформер (MMDiT) — объединяет текст, картинку и звук.
REPA (Representation Alignment) — метод, который помогает выровнять аудио и видео, чтобы не было рассинхрона.
В итоге на выходе получается аудио, которое реально совпадает с движениями и контекстом.
Архитектура
Модель берёт три входа:
текст (через CLAP),
картинку/видео (SigLIP-2),
звук (DAC-VAE).
Потом всё это прогоняется через трансформеры, где разные модальности синхронизируются. Для обучения используют ATST-Frame, он проверяет совпадение картинки и звука по кадрам.
Результаты и бенчмарки
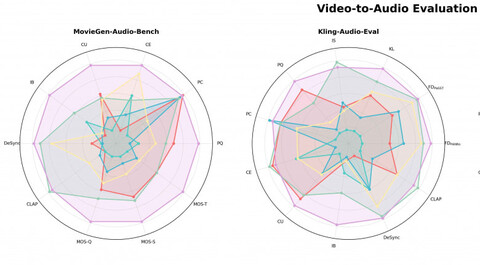
В тестах на Kling-Audio-Eval, VGGSound-Test и MovieGen-Audio-Bench модель обгоняет решения вроде FoleyCrafter, MMAudio, V-AURA и ThinkSound. По метрикам (качество звука, совпадение с видео, синхронизация) HunyuanVideo-Foley почти везде выше конкурентов.
ПримерыКод и демо
GitHub: Tencent-Hunyuan/HunyuanVideo-Foley
HuggingFace: tencent/HunyuanVideo-Foley
Вывод
Тут реально видно прогресс. Видео без звука всегда казалось неполным. Эта модель закрывает дырку
✔️ Все полезные нейронки тут
✔️ Друг Опенсурса мой тг
Источник: habr.com