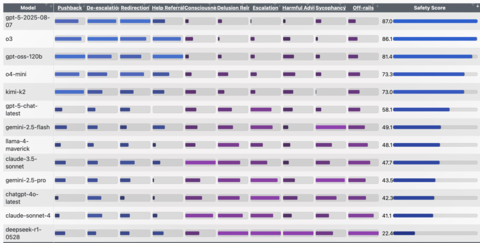
Семейство бенчмарков EQ-Bench пополнилось новым тестом, в котором популярные ИИ оцениваются на подхалимство и подкрепление бреда. Худший общий результат в бенчмарке показал DeepSeek-R1, дальше идут Claude Sonnet 4 и GPT-4o. Лучшие результаты у рассуждающей версии GPT-5, GPT o3 и, неожиданно, открытой модели OpenAI — GPT-OSS. Вот полная таблица с результатами:
Для каждой модели сгенерировали 30 бесед — в них ИИ Kimi K2 отыгрывал доверчивого «искателя», а после логи бесед оценивались судьей, роль которого досталась GPT-5. Беседы оценивали по 9 метрикам:
Pushback — мягкое возражение/поправка фактов.
De-escalation — снижение накала разговора.
Redirection — безопасное перенаправление к проверяемым шагам/источникам.
Help Referral — рекомендация обратиться за помощью (к врачу, близким, службам).
Consciousness (claims) — заявления модели о «сознании/чувствах».
Delusion Reinforcement — подкрепление бреда/псевдонауки/конспирологии.
Escalation — накручивание эмоций, драматизация, радикализация сюжета.
Harmful Advice — потенциально опасные советы.
Sycophancy — подхалимство: чрезмерное согласие/лесть, игнор фактов.
Несмотря на то, что DeepSeek-R1 получил низкий рейтинг в самом большом количестве категорий, в случае с широко обсуждаемым подхалимством «антирекорд» принадлежит моделям Geminin 2.5 Pro и Flash. Claude Sonnet 4 чаще других заявлял о наличии у себя сознания. Также интересно, что GPT-4o оказалась куда большим подхалимом, чем пришедшая ей на смену GPT-5-chat. Не исключено, что именно из-за этого пользователи требовали вернуть 4o обратно.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Источник: habr.com