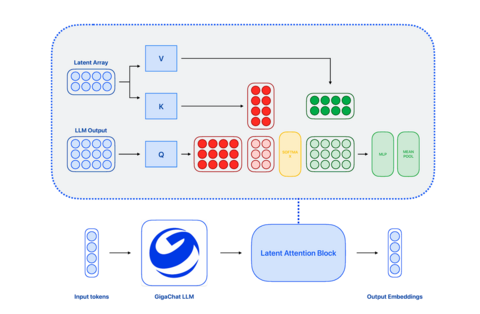
Исследователи «Сбера» создали модель GigaEmbeddings, которая улучшает поиск и создание чат-ботов, . По словам разработчиков, новая модель помогает бизнесу обрабатывать русский язык с помощью искусственного интеллекта. Статья, посвящённая GigaEmbeddings, была представлена на конференции ACL 2025. В статье описана сама модель обработки текстов.
GigaEmbeddings построена на основе GigaChat-3B. Новая модель проходила три этапа обучения: предварительное обучение, точная настройка и мультизадачное обучение. Архитектура оптимизирована, параметры модели уменьшены на 25%, но качество не пострадало. Модель доступна на GitVerse и HuggingFace.
Как объяснили в «Сбере», ранее бизнесу не хватало хороших инструментов для работы с русским языком. Существующие решения либо требовали больших вычислительных ресурсов, либо плохо решали задачи поиска, классификации и кластеризации текстов. GigaEmbeddings решает эти проблемы.
Модель GigaEmbeddings подходит для таких задач, как умный поиск в e‑commerce (например, понимание запросов на маркетплейсах), создание чат‑ботов с расширенными возможностями (RAG‑системы), анализ обращений клиентов в банках и финтехе, а также для персонализированных рекомендаций в медиа и ритейле.
Технический директор GigaChat «Сбербанка» Фёдор Минькин заявил, что GigaEmbeddings закрывает потребность рынка в качественных NLP‑решениях для русского языка. Наша платформа помогает бизнесу оптимизировать работу с текстами — от поиска и рекомендаций до передовых RAG‑систем в чат‑ботах.
Источник: habr.com