Hierarchical Reasoning Model, (HRM) — рекуррентная архитектура, которая черпает вдохновение в принципах работы человеческого мозга.
В ее основе лежат 2 взаимозависимых рекуррентных модуля:
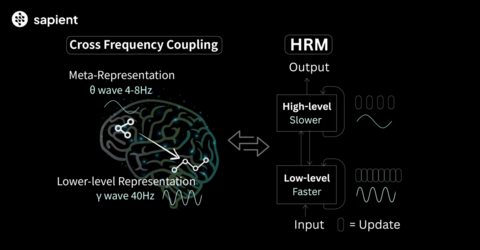
Первый, высокоуровневый модуль (H-модуль), отвечает за медленное, абстрактное планирование, подобно тета-волнам в мозге.
Второй, низкоуровневый модуль (L-модуль), занимается быстрыми и детализированными вычислениями, аналогично гамма-волнам.
Эта структура дает модели достигать вычислительной глубины, необходимой для сложных рассуждений, при этом сохраняя стабильность и эффективность во время обучения, чего так не хватает стандартным трансформерам.
Взаимодействие модулей назвали «иерархической конвергенцией»
Процесс кардинально отличается от того, что происходит в обычных рекуррентных сетях, которые склонны к преждевременной сходимости, когда их скрытое состояние быстро стабилизируется, и дальнейшие вычисления практически прекращаются. В HRM все иначе:
Сначала быстрый L-модуль выполняет серию итераций, находя локальное равновесие для текущего шага задачи. Его итоговое состояние передается медленному H-модулю.
H-модуль, в свою очередь, осмысливает полученный результат, выполняет один шаг собственного, более абстрактного обновления и задает совершенно новый контекст для L-модуля.
Таким образом, вычислительный путь низкоуровневого модуля перезапускается, направляя его к новой точке локального равновесия. Механизм не дает системе застрять и позволяет ей последовательно выполнять множество различных, но взаимосвязанных этапов решения, выстраивая длинные логические цепочки.
Тестовая модель HRM с 27 млн. параметров, обученная всего на 1000 примерах без какого-либо претрейна или CoT-пар, показала неожиданно высокие результаты. На задачах, требующих глубокого поиска и перебора вариантов (Sudoku-Extreme) и поиск оптимального пути (Maze 30×30), HRM достигла почти идеальной точности, а вот CoT-методы полностью провалились с результатом 0%.
На бенчмарке ARC-AGI-1, HRM показывает точность в 40.3%. Для сравнения, o3-mini-high показала 34.5%, а Claude 3.7 с контекстом 8K — 21.2%.
Веса моделей для самостоятельного воспроизведения тестов:
ARC-AGI-2;Sudoku 9×9 Extreme (1000 examples);Maze 30×30 Hard (1000 examples);
Лицензирование: Apache 2.0 License.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Источник: habr.com