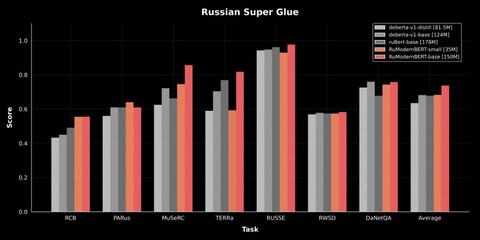
VK выложила в открытый доступ нейросетевую модель RuModernBERT для обработки разговорного русского языка. RuModernBERT понимает длинные тексты целиком, без разбиения на части. Модель работает локально и не использует внешние API. По словам VK, это снижает нагрузку на инфраструктуру.
Инженеры могут применять RuModernBERT для задач по обработке текста. Например, для извлечения информации, анализа тональности, поиска и ранжирования в сервисах и приложениях. Модель понимает длинные и сложные запросы. Она помогает находить нужную информацию, видео, товары или документы.
RuModernBERT обучена на 2 трлн токенов. Использовались данные на русском, английском языках и коде. Максимальная длина контекста — до 8 192 токенов. Для обучения брали разные источники: книги, статьи, посты и комментарии в соцсетях. Это позволяет модели работать с современным текстом и учитывать разговорную речь.
Доступны версии модели на 150 млн параметров и облегчённая — на 35 млн. Это даёт инженерам возможность выбрать нужную конфигурацию. Обновлены и две дополнительные версии: USER и USER2. Они улучшают группировку и поиск похожей информации. В USER2 встроена технология, которая уменьшает объём данных почти без потери точности.
RuModernBERT построена на современной архитектуре. За счёт этого обучение и развертывание модели происходят на 10–20% быстрее. Обработка длинных текстов — в 2–3 раза быстрее по сравнению с ModernBERT*.
На валидационном датасете RuModernBERT показала лучшие результаты по обработке русского языка, чем другие модели. Её уже внедрили в сервисы VK. Все модели доступны на платформе Hugging Face.
Источник: habr.com