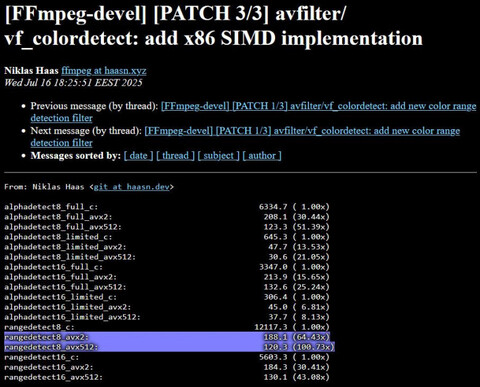
Разработчики открытого мультимедиа‑пакета FFmpeg заявили, что смогли добиться 100-кратной производительности в работе функции rangedetect8_avx512, благодаря новому патчу и искусству рукописного ассемблерного кода.
Исходный код фильтра был переписан с использованием концепции обработки SIMD (Single Instruction, Multiple Data) для значительно улучшенной параллельной обработки на современных мощных процессорах. Очевидно, что компиляторы — программы, которые берут код на языке высокого уровня и выдают ассемблерный (машинный) код — всё ещё не могут конкурировать с рукописным ассемблером. Или, как написали в команде FFmpeg, можно сказать: «Распределитель регистров — отстой для компиляторов».
В ноябре 2024 года разработчики проекта FFmpeg сообщили о реализации новых ассемблерных оптимизаций, в которых, благодаря применению набора инструкций AVX-512, удалось ускорить в 94 раза некоторые операции, применяемые при декодировании видео, по сравнению базовой реализацией, написанной на языке C без использования SIMD‑инструкций. Инструкции AVX-512 доступны в процессорах AMD на базе микроархитектур Zen 4 и 5, и в процессорах Intel на базе таких микроархитектур, как Skylake‑X, Ice Lake, Tiger Lake и Rocket Lake.
Источник: habr.com