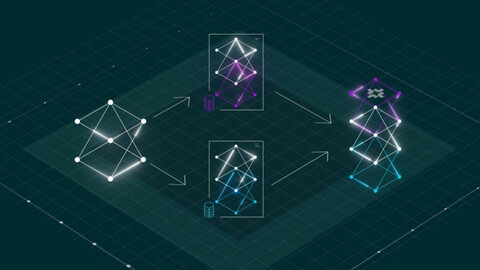
FlexOlmo, разработанный в Институте искусственного интеллекта Аллена, демонстрирует возможность совместной работы организаций над языковыми моделями на основе локальных наборов данных без передачи конфиденциальных данных.
FlexOlmo основан на архитектуре Mixture-of-Experts (MoE), где каждый эксперт соответствует модулю прямой передачи (FFN), обученному независимо. Фиксированная общедоступная модель (обозначается как Mpub) служит общим якорем. Каждый владелец данных обучает эксперта Mi на своём частном наборе данных D_i, в то время как все слои внимания и другие параметры, не относящиеся к экспертам, остаются замороженными.
Основная проблема, связанная с независимыми экспертами, — это координация. FlexOlmo решает эту проблему, используя замороженную общедоступную модель в качестве эталона. Общедоступный эксперт не меняется в процессе обучения, в то время как новые эксперты обучаются на локальных данных. Таким образом, все эксперты соответствуют одной и той же эталонной модели и могут быть объединены без дополнительного переобучения.
Гибкость в отношении конфиденциальных данных
FlexOlmo хорошо подходит для случаев, когда необходимо строго контролировать доступ к данным. Источники данных можно активировать или деактивировать в зависимости от приложения. Например, токсичный контент может быть включен для исследования, но исключен из общего доступа.
Исследователи продемонстрировали это, удалив эксперта по новостям в ходе тестового запуска. Как и ожидалось, производительность при выполнении задач, связанных с новостями, снизилась, но результаты в других областях остались стабильными.
Когда эксперт по новостям удаляется из FlexOlmo, производительность при выполнении новостных задач снижается, но результаты в других областях остаются практически неизменными
Даже если лицензии изменятся или истечёт срок действия прав на использование, источники данных можно будет деактивировать без переобучения всей модели. В итоговой модели 37 миллиардов параметров, из которых 20 миллиардов активны.
Повышение производительности в реальных тестах
Команда оценила FlexOlmo, используя общедоступные данные и семь специализированных наборов данных: новости, художественное письмо, код, научные статьи, образовательные тексты, математика и контент на Reddit.
При тестировании на 31 задаче FlexOlmo показал в среднем на 41% более высокие результаты по сравнению с моделью, обученной только на общедоступных данных. В целом FlexOlmo превзошёл гипотетическую модель, имеющую доступ ко всем данным, при тех же вычислительных затратах. Только модель, которая была обучена на полном наборе данных с использованием удвоенного объёма ресурсов, продемонстрировала несколько более высокие показатели.
Архитектура FlexOlmo приводит лишь к незначительному снижению производительности в более общих тестах
Поскольку владельцы данных предоставляют доступ только к обученным моделям, риск утечки минимален. В ходе тестирования атаки с целью восстановления обучающих данных были успешными лишь в 0,7% случаев. Для организаций, которые работают с информацией, требующей особой секретности, FlexOlmo предоставляет возможность обучения с соблюдением дифференциальной конфиденциальности. Это гарантирует формальную защиту данных. Каждый участник может включить эту опцию самостоятельно. Институт Аллена также выпустил OLMoTrace — инструмент для отслеживания связи между результатами работы языковой модели и источниками её обучения.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!
Перевод, источник новости здесь.
Источник: habr.com