В инженерной команде Cloudflare раскрыли причину часового глобального сбоя в работе публичного DNS-резолвера 1.1.1.1 и сетевого сервиса Gateway plain text DNS. Инцидент произошёл 14 июля 2025 года и затронул всех пользователей. В качестве временной меры для решения сетевых проблем клиентам Cloudflare и всем остальным пользователям предлагалось выполнять DNS-запросы с помощью другого провайдера.
Сбой произошёл из-за неправильной настройки устаревших систем, используемых для поддержки инфраструктуры, которая объявляет IP-адреса Cloudflare в Интернете.
Спустя чуть более часа после начала инцидента инженеры Cloudflare смогли восстановить работу DNS-резолвера 1.1.1.1 в полном объёме. Оказалось, что сетевая проблема в виде ошибки конфигурации была в IT-инфраструктуре компании с 6 июня, но не проявляла себя из-за локальных ограничений в системе.
Почти все сервисы Cloudflare доступны в Интернете с помощью метода маршрутизации anycast. Эта технология позволяет обслуживать трафик популярных сервисов в различных местах Интернета, увеличивая пропускную способность и производительность. Это лучший способ обеспечить глобальное управление трафиком, но также означает, что проблемы с объявлением этого адресного пространства могут привести к глобальному сбою.
Cloudflare анонсирует маршруты anycast в Интернет, чтобы трафик по адресам доставлялся в центр обработки данных Cloudflare, предоставляя услуги из множества разных мест. Большинство сервисов Cloudflare, например, публичный DNS-резолвер 1.1.1.1, предоставляются глобально, но некоторые сервисы компании ограничены определёнными регионами.
Эти сервисы являются частью услуги Data Localization Suite (DLS), который позволяет клиентам настраивать Cloudflare различными способами для соответствия требованиям в разных странах и регионах. Один из способов, с помощью которого Cloudflare управляет этими различными требованиями, заключается в том, чтобы гарантировать, что IP-адреса нужного сервиса DLS доступны из Интернета только там, где это необходимо, что обеспечивает корректную обработку трафика по всему миру. У конкретного сервиса есть соответствующая «топология сервиса», то есть трафик сервиса DLS должен направляться только в определённый набор местоположений.
6 июня во время подготовки топологии сервиса для будущего сервиса DLS была допущена ошибка конфигурации: префиксы, связанные со сервисом DNS-резолвера 1.1.1.1, были случайно добавлены вместе с префиксами, предназначенными для нового сервиса DLS. Эта ошибка конфигурации не проявилась в рабочей сети, поскольку новый сервис DLS ещё не использовался, но она подготовила почву для сбоя 14 июля. Поскольку немедленных изменений в рабочей сети не было (изменение конфигурации было внесено для сервиса DLS, который ещё не был запущен в эксплуатацию), это не повлияло на конечных пользователей.
Также никакие оповещения не были предоставлены для инженеров, поскольку трафик не изменился, но ошибка конфигурации осталась в системе незамеченной до следующего релиза.
14 июля изменение конфигурации было внесено для той же службы DLS. Изменение прикрепило тестовую локацию к нерабочей службе; сама эта локация не была запущена, но изменение вызвало глобальное обновление конфигурации сети. Из-за ранее допущенной ошибки конфигурации, связывающей IP-адреса резолвера 1.1.1.1 с нашей нерабочей службой, эти IP-адреса 1.1.1.1 были случайно включены при изменении настроек нерабочей службы. Префиксы резолвера 1.1.1.1 начали отзываться из рабочих дата-центров Cloudflare по всему миру.
Через 4 минуты DNS-трафик к резолверу 1.1.1.1 начал падать по всему миру.
Через 2 минуты зафиксировано не связанное с причиной событие: перехват BGP-источника 1.1.1.0/24, выявленный в результате отзыва маршрутов от Cloudflare. Это не было причиной сбоя службы, а представляло собой не связанную с ней проблему, которая внезапно проявилась после отзыва префикса Cloudflare. Весь трафик, поступающий в Cloudflare через службы резолвера 1.1.1.1 по этим IP-адресам, был затронут. Трафик к каждому из этих адресов также был затронут по соответствующим маршрутам.
Через 7 минут начинают срабатывать внутренние оповещения о проблеме с работоспособностью служб для DNS-резолвера 1.1.1.1.
Через 19 минут был инициирован откат для восстановления предыдущей конфигурации. Для ускорения полного восстановления сервиса перед выполнением вручную запущенное действие проверяется в тестовых средах.
Через 34 минуты оповещения о проблеме с резолвером 1.1.1.1 были сняты, и трафик DNS на префиксах резолвера начал возвращаться к нормальному уровню.
В итоге через 66 минут инженеры Cloudflare смогли устранить проблему и вернуть работоспособность DNS-резолвера 1.1.1.1.
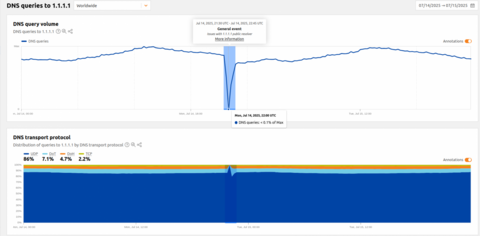
После начала инцидента в Cloudflare заметили немедленное и значительное снижение количества запросов по протоколам UDP, TCP и DNS через TLS (DoT). У большинства пользователей в качестве DNS-серверов настроены следующие адреса: 1.1.1.1, 1.0.0.1, 2606:4700:4700::1111 или 2606:4700:4700::1001. Ниже представлена частота запросов для каждого протокола и степень их влияния во время инцидента:
Стоит отметить, что трафик DoH (DNS-over-HTTPS) оставался относительно стабильным, поскольку большинство пользователей DoH используют домен cloudflare-dns.com, настроенный вручную или через браузер, для доступа к публичному DNS-резолверу, а не по IP-адресу. DoH оставался доступным, и трафик практически не пострадал, поскольку cloudflare-dns.com использует другой набор IP-адресов. Некоторая часть DNS-трафика по UDP, также использующего другие IP-адреса, также практически не пострадала. Поскольку соответствующие префиксы были отменены, трафик, отправляемый на эти адреса, не мог достичь Cloudflare. Это можно увидеть на временной шкале объявлений BGP для 1.1.1.0/24:
Если посмотреть на частоту запросов к отозванным IP-адресам, можно заметить, что в течение инцидента трафик практически не поступает. После применения первоначального исправления в 22:20 UTC наблюдается значительный всплеск трафика, после чего он снова снижается. Этот всплеск обусловлен повторными запросами клиентов. Когда инженеры снова начали анонсировать отозванные префиксы, запросы снова смогли достичь Cloudflare. Маршрутизация была восстановлена во всех точках только к 22:54 UTC, и трафик вернулся практически к нормальному уровню.
«Мы вернулись к предыдущей конфигурации в 22:20 UTC. Практически сразу же мы начали повторно объявлять префиксы BGP, которые были ранее отозваны с маршрутизаторов, включая 1.1.1.0/24. Это восстановило уровень трафика 1.1.1.1 примерно до 77% от уровня до инцидента. Однако за период с момента начала сбоя примерно 23% парка пограничных серверов (edge servers) были автоматически перенастроены для удаления необходимых привязок IP‑адресов в результате изменения топологии. Чтобы вернуть конфигурации, эти серверы потребовалось перенастроить с помощью нашей системы управления изменениями, которая по умолчанию не является мгновенным процессом в целях безопасности.
Процесс восстановления привязок IP‑адресов обычно занимает некоторое время, поскольку сеть в отдельных местах спроектирована так, чтобы обновляться в течение нескольких часов. Мы реализуем постепенное развёртывание, а не на всех узлах одновременно, чтобы избежать дополнительного влияния. Однако, учитывая серьёзность инцидента, мы ускорили внедрение исправления после проверки изменений в тестовых точках, чтобы восстановить работу сети как можно быстрее и безопаснее. В 22:54 UTC трафик был в пределах нормы.
Сервис DNS‑резолвера Cloudflare 1.1.1.1 стал жертвой внутренней ошибки конфигурации. Приносим извинения за сбои в работе наших клиентов, вызванные этим инцидентом. Мы активно работаем над необходимыми улучшениями, чтобы обеспечить более стабильную работу в будущем и предотвратить повторение подобной проблемы»,
— подытожили в Cloudflare.
Источник: habr.com