Как известно, вчера вышла новая итерация ИИ от xAI — Grok 4.Пока в техсообществе считалось хорошим тоном нахваливать Claude Opus, немного — GPT‑4o, и снисходительно хихикать над творением Илона Маска, Grok ворвался и внезапно взорвал танцпол. По крайней мере — в бенчмарках.
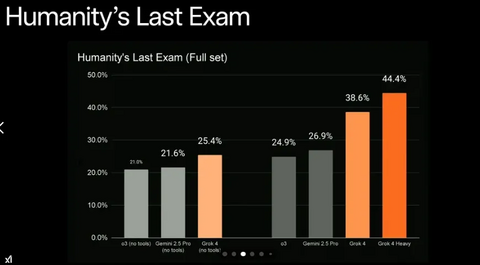
Humanity’s Last ExamGrok 4 и особенно Grok 4 Heavy обошли ближайших конкурентов — в том числе Gemini 1.5/2.5 Pro — с солидным отрывом.
Что это такое: Humanity’s Last Exam — это один из самых амбициозных и по-настоящему сложных бенчмарков для оценки уровня искусственного интеллекта, приближённого к человеческому мышлению. Его невозможно пройти просто доставая информации из интернета или памяти без настоящего логического мышления. К этому экзамену нельзя заранее подготвиться.
Название является шуткой обыгрывающей то, что если ИИ его пройдёт — то человечество больше не нужно. Или не совсем шуткой. Когда ИИ достигнет в нём результата близкого к 100% — что это? Правильно, AGI.
Как он устроен: HLE включает в себя вопросы из реальных школьных, университетских и олимпиадных тестов, которые требуют логики, интуиции, обобщения и многоступенчатого рассуждения. Чтобы модели нельзя было натренировать, тест изолирован от «натаскивания», как это бывает с популярными экзаменами вроде SAT, GRE и т. д.
Почему это важно для AGI: Если ИИ хорошо справляется с HLE — это признак приближения к General Intelligence, а не просто хорошо адаптированный к тесту fine‑tuned болтун. В отличие от стандартных бенчмарков, HLE проверяет глубину понимания, а не натренированность на датасете.
ARC-AGIВ этом тесте Grok 4 тоже опередил всех. И да, он делает это без цены в $0.30 за токен.
Что это такое: ARC-AGI (или ARC-Challenge) — это бенчмарк из серии Abstraction and Reasoning Corpus, разработанный для оценки способности ИИ к абстрактному мышлению, переносу знаний и решению задач без обучения на примерах.
Как он устроен: Каждая задача — это набор input‑output примеров: ИИ видит лишь несколько пар «вход‑выход», а затем даётся новый «вход», к которому нужно придумать правильный «выход». Инструкций и пояснений нет. Всё нужно понять из примеров.
Задачи выглядят как простые пиксельные матрицы (обычно 2D‑сетки), но логика за ними часто нетривиальна: трансформации, паттерны, правила симметрии, циклы, исключения и пр.
Почему это важно для AGI: Это не то, чему можно просто обучиться на большом корпусе текста — модель должна догадаться до правила. ARC-AGI специально разработан так, чтобы даже state-of-the-art модели не могли натренироваться на похожих задачах. ARC-AGI оценивает универсальность мышления, способность к обобщению, аналогичную человеческому понятию «сообразительности».
Vending-BenchGrok 4 оказался неожиданно хорош не только в экзаменах, но и в управлении — пусть и виртуальным — бизнесом.
Что это такое: в отличие от прошлых бенчмарков, этот разработан для тестирования не однократного успеха, а способности ИИ‑агентов сохранять стабильность решения интеллектуальных задач в автономном режиме. В это сценарии ИИ управляет виртуальным автоматом — принимает заказ, устанавливает цены, следит за запасами, пополняет их, оплачивает ежедневные сборы. Обычные LLM отлично справляются с короткими заданиями, но рано или поздно «срываются»: забывают сделать заказ, неправильно интерпретируют статус, входят в бессмысленные циклы. Модели нужно планировать, выбирать нужные инструменты (API, читать мануалы, искать, делаь финрасчёты загодя) — т. е. выступать не пассивным объектом взаимодействия, а по‑настоящему активным субъектом.
Почему это важно для AGI: Большинство современных моделей умеют решать задачи длиной в один или несколько запросов. Но теоретический AGI должен уметь действовать автономно в долгий срок, обрабатывать ввод, делать выбор, корректировать поведение, не зацикливаться и не сбиваться с фокуса своей задачи.
Vending‑Bench — это попытка симулировать автономную жизнь ИИ в узком, но всё же сценарии: не просто отвечать на промпты извне, а вести бизнес.
Другие бенчиКакой тест не возьми — везде Grok 4 в лидерахGPQA (Graduate-Level Physics QA)
Вопросы уровня аспирантуры по физике. Не списать, не нагуглить. Grok справляется.
AIME25 (American Invitational Mathematics Exam, 2025)
Олимпиада по математике для школьников в США. Сложно, нестандартно. Grok на высоте.
LCB (MATH Labeled Chain-of-Thought Benchmark)
Математические задачи с обязательной цепочкой рассуждений. Проверяется не просто ответ, а логика рассуждения. Grok держится лучше GPT‑4o и Claude.
HMMT25 (Harvard-MIT Math Tournament, 2025)
Математические задачи олимпиадного уровня из ежегодного турнира для старшеклассников. Проверяют комбинаторику, теорию чисел и нестандартное мышление.
USAMO25 (USA Mathematical Olympiad, 2025)
Топовые математические олимпиады — с акцентом на доказательства, теорию чисел, комбинаторику. Здесь не выживают просто убедительно жонглирующие словами LLM. Grok снова в топе.
Вместо выводов
Если вы ещё вчера смеялись над «Грокгейтом» в X (твиттор) — мол, что можно ожидать от модели, которую пользователи соцсети два дня назад развели (джейлбрекнули) на политический троллинг в самом кринжовом его проявлении — то я бы пересмотрел позицию.
Стоит ли платить 30$ (на целых 10$ больше, чем в большинстве мейнстримных моделей) в месяц Илону за самые красивые бенчи? А 300$ (!) за Grok 4 Heavy, а ?Если вы просто общаетесь с ИИ ради эмпатии и сеансов психоанализа — нет, GPT‑4o и Claude всё ещё милее.Однако впервые платить 30 баксов в месяц Илону получило веское обоснование.
Дорого? Да. Особенно учитывая, что у большинства из нас и так подписка минимум 20$ на ChatGPT и/или Claude.Любопытно? Очень.AGI это? Пока нет, выдыхаем.P. S. Бесплатного тира у Grok 4 нет. Заход в «AGI для народа» — строго по прайсу.
Источник: habr.com