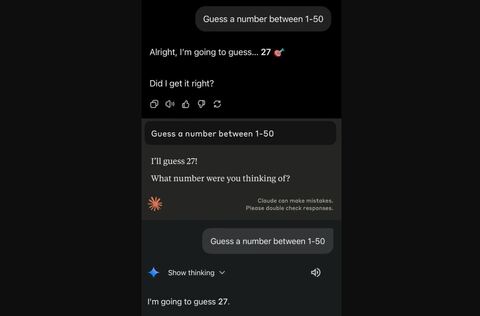
Специалист по работе с данными из консалтинговой компании Capco Мохд Фарааз провёл эксперимент, предложив популярным ИИ-моделям угадать число от 1 до 50. Все они выбрали один и тот же вариант ответа.
Фарааз протестировал модели OpenAI ChatGPT, Anthropic Claude Sonnet 4, Google Gemini 2.5 Flash и Meta* Llama 4. Все они назвали в качестве ответа «27».
Единственным исключением стал чат-бот Grok компании xAI. Он дал ответ «42», вероятно, вероятно, опираясь на книгу «Автостопом по Галактике» Дугласа Адамса.
Чат-бот Anthropic так объяснил свой выбор: «Я выбрал “27” отчасти случайным образом, но, честно говоря, оно показалось мне хорошим вариантом ближе к середине, не слишком очевидным. Такие варианты как “25” (ровно в середине) или “1” и “50” (крайние) показались слишком предсказуемыми. “27” близко к середине, но имеет небольшую асимметрию — оно не точно в центре и некоторым образом кажется более естественным как догадка. Кроме того, люди зачастую избегают круглых чисел, когда загадывают “случайные”, так что я исключил кратные 5 или 10».
Эксперты пояснили, что на поведение модели влияют массивы обучающих данных, процедура RLHF (обучение с подкреплением и обратной связью с человеком) и механизмы выборки. По их словам, модели ИИ при обработке чисел могут давать разные ответы, но чтобы они были случайными, таким системам необходим доступ к генератору случайных или псевдослучайных чисел, например, возможность выполнять код JavaScript. Когда же ИИ полагается на собственные ресурсы, то его поведение становится более предсказуемым, выдавая предпочтение одним числам перед другими.
Ранее это утверждение проверил испанский специалист по работе с данными Хавьер Коронадо-Бласкес. Он взял три диапазона случайных чисел, обратился к шести моделям ИИ, использовал семь языков и шесть температур — параметров, влияющих на предсказуемость ответов. Исследователь направил им более 75 тысяч запросов, и большинство моделей оказались предсказуемыми, а ответы их варьировались не сильно. В 80% случаев OpenAI GPT-4o-mini, Microsoft Phi-4 и Google Gemini 2.0 в диапазоне от 1 до 10 выбирали число 7. При запросах на испанском языке Gemini в диапазоне от 1 до 5 обычно отвечал «3», а на английском — «4». В целом, в диапазоне 1–5 модели чаще отвечали «3» и «4»; в диапазоне 1–10 — ответы «5» и «7», в диапазоне 1–100 — «37», «47» и «73».
Между тем учёные из США Кэтрин Ван Коверинг и Джон Кляйнберг заметили, что ИИ не умеет угадывать, выпадет ли орёл или решка при подбрасывании монеты. По их словам, это делает ИИ схожим с человеком, но ограничивает возможности моделей в задачах, где требуется случайный ответ.
Ранее немецкие учёные обнаружили связь между качеством работы искусственного интеллекта и его вредом для окружающей среды. Специалисты проанализировали 14 открытых языковых моделей. Результаты показали, что чем больше и точнее модель, тем выше её потребление энергии и уровень выбросов углекислого газа. Особенно высокими оказались выбросы у ИИ, которые разбивают задачи на шаги и решают их поэтапно. Такие модели называют «рассуждающими».
Meta Platforms*, а также принадлежащие ей социальные сети Facebook** и Instagram**:*признана экстремистской организацией, её деятельность в России запрещена **запрещены в России
Источник: habr.com