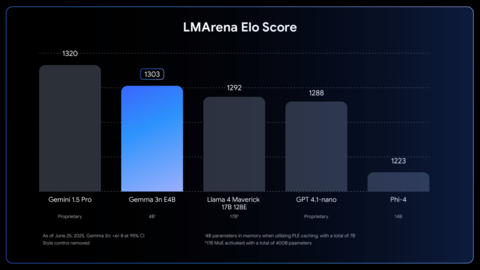
В компании рекламируют Gemma 3n как первую компактную модель, которая достигла рейтинга 1300 на LMArena:
Модель доступна в двух базовых версиях E2B и E4B на 5 и 8 млрд «сырых» параметров и 2 и 4 миллиарда эффективных параметров, которые размещаются в памяти устройства. Экономию видеопамяти обеспечивает приём Per-Layer Embeddings («встраивания по слоям»): половина весов остаётся на CPU, а в VRAM загружается лишь «ядро» трансформера. Благодаря этой и прочим оптимизациям, модели требуют 2 и 3 ГБ видеопамяти соответственно — то есть, их можно запускать на смартфоне с 8 ГБ памяти. Для энтузиастов заготовлена архитектура MatFormer — можно взять большую модель E4B и самостоятельно вырезать из нее лишние слои, подобрав собственный размер между 2 и 4 млрд параметров под своё устройство.
По словам команды Google, Gemma 3n «понимает» 140 + языков и принимает до 128 000 токенов. Это порядка 100 страниц А4, — то есть модель способна резюмировать целую книгу прямо на устройстве. Модель полностью мультимодальна и сразу «из коробки» принимает текст, изображения, звук и видео. Для аудио встроен кодировщик USM (универсальная речевая модель), способный распознавать речь и переводить её на другой язык. Новый визуальный кодировщик MobileNet-V5-300M оптимизирован под чипы смартфонов и на последней версии Google Pixel распознает видео частотой до 60 кадров в секунду.
Gemma 3n распространяется под лицензией Gemma (условия, схожие с Apache 2.0), но требует соблюдать политику «Ответственного генеративного ИИ» Google. Модель уже доступна для скачивания на Hugging Face и Kaggle и для локального вывода на llama.cpp, Ollama, LM Studio, MLX (Apple Silicon).
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой точки зрения.
Источник: habr.com