Microsoft презентовала малую языковую модель Mu, которая встроена в Windows 11 и будет работать локально. Эта модель обеспечивает работу агента в настройках, доступного для инсайдеров Windows в Dev Channel с ПК Copilot+, путём сопоставления запросов ввода на естественном языке с вызовами функций настроек.
Нейронный процессор (NPU) отвечает со скоростью более 100 токенов в секунду. При разработке Mu использовали данные работы на NPU Phi Silica.
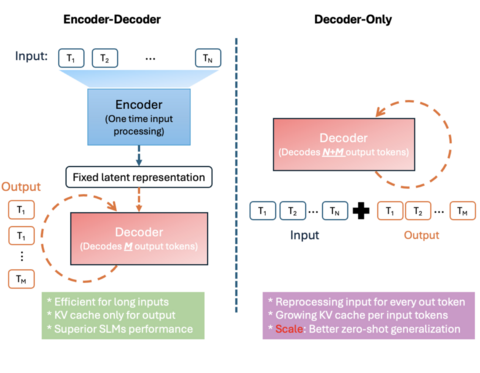
Модель разработана с нуля. Это языковая модель кодера-декодера 330M, оптимизированная для мелкомасштабного развёртывания, особенно на NPU на ПК Copilot+. Она следует архитектуре преобразователя кодера-декодера, то есть кодер сначала преобразует вход в скрытое представление фиксированной длины, а затем декодер генерирует выходные токены на основе этого представления. На практике это приводит к снижению задержки и повышению пропускной способности на специализированном оборудовании. Например, на Qualcomm Hexagon NPU применение Mu позволила достичь снижения задержки на 47% и в 4,7 раза более высокой скорости декодирования по сравнению с моделью с одним только декодером аналогичного размера.
Конструкция Mu была тщательно настроена для ограничений и возможностей NPU. Это касается архитектуры модели и форм параметров. Размеры слоев модели соответствуют предпочтительным размерам тензора NPU и единицам векторизации, гарантируя, что умножение матриц и другие операции будут выполняться с максимальной эффективностью. Распределение параметров между кодером и декодером тоже оптимизировали — эмпирически отдав предпочтение разделению 2/3–1/3 (например, 32 слоя кодера против 12 слоев декодера в одной конфигурации).
Mu использует распределение веса в определённых компонентах для сокращения общего количества параметров. Например, она связывает вложения входных и выходных данных, так что один набор весов используется как для представления входных токенов, так и для генерации выходных. Это не только экономит память, но и улучшает согласованность между кодирующими и декодирующими словарями.
Наконец, Mu ограничивает свои операции теми оптимизированными для NPU операторами, которые поддерживаются средой выполнения развёртывания. Такие методы обучения, как графики разогрева-стабильности-распада и оптимизатор Muon, использовались для дальнейшего улучшения производительности.
Mu обучали с использованием графических процессоров A100 в Azure Machine Learning, проходя через несколько этапов. Сначала модель прошла предварительное обучение на сотнях миллиардов образовательных токенов высочайшего качества, чтобы изучить синтаксис языка, грамматику, семантику и получить знания.
Для дальнейшего повышения точности применили дистилляцию из моделей Phi.
Работу Mu оценили, выполнив тонкую настройку на нескольких задачах, включая SQUAD, CodeXGlue и агент настроек Windows. При сравнении Mu с аналогично настроенной Phi-3.5-mini выяснилось, что первая почти сопоставима по производительности со второй, несмотря на то, что она в десять раз меньше.
Квантование после обучения (PTQ) использовали для преобразования весов и активаций модели из представлений с плавающей точкой в целочисленные представления — в основном 8- и 16-битные.
Наконец, Microsoft тесно работала с AMD, Intel и Qualcomm, чтобы гарантировать, что квантованные операции при запуске Mu будут оптимизированы для целевых NPU. Работа включала настройку математических операторов, согласование с шаблонами выполнения, специфичными для оборудования, и проверку производительности на разных чипах. В итоге Mu генерирует выходные данные со скоростью более 200 токенов в секунду на Surface Laptop 7.
Чтобы повысить простоту использования Mu в Windows, разработчики сосредоточились на решении проблемы изменения сотен системных настроек. Цель состояла в том, чтобы создать агента на базе ИИ в настройках, который понимает естественный язык и плавно изменяет соответствующие отменяемые настройки.
Чтобы повысить точность модели, её обучение масштабировали до 3,6 млн образцов (1300x) и расширили примерно с 50 настроек до сотен. Тонкая настройка модели позволила достичь времени отклика менее 500 миллисекунд.
При этом разработчики заметили, что модель лучше всего работала с многословными запросами, которые передавали чёткое намерение. Чтобы устранить этот пробел, агент интегрировали в поле поиска настроек, чтобы преобразовывать короткие запросы в многословные. Однако даже простой запрос, такой как «Увеличить яркость», мог ссылаться на несколько изменений настроек, например, если у пользователя два монитора. Чтобы решить эту проблему, разработчики уточнили обучающие данные, чтобы расставить приоритеты для наиболее используемых настроек.
Модель уже доступна для участников программы Windows Insiders.
Источник: habr.com