Помните недавние твиты больших шишек из мира ИИ? Андрей Карпатый (экс‑OpenAI) закинул идею: а что если сравнивать большие языковые модели (LLM) не по скучным бенчмаркам, а в играх? Где надо думать, взаимодействовать, а не просто выдавать ответы. «Отличная мысль, — подхватил Ноам Браун из OpenAI, — вот бы увидеть, как ведущие боты сыграют в Diplomacy!»
Карпатый согласился: мол, сложность‑то как раз в переговорах между игроками, а не в правилах. Илон Маск отметился лаконичным «Yeah», а нобелевский лауреат Демис Хассабис из DeepMind просто написал: «Круто!» Идея витала в воздухе, и энтузиаст Алекс Даффи решил: «А почему бы и нет?»
В понедельник он выложил пост под говорящим названием: «Мы предложили топовым ИИ‑моделям сыграть в Diplomacy. Вот кто победил». И да, это не просто отчёт — за играми до сих пор можно следить в реальном времени на Twitch! Сам Даффи, кстати, курирует обучение ИИ в консалтинге Every.
Что за зверь — Diplomacy?
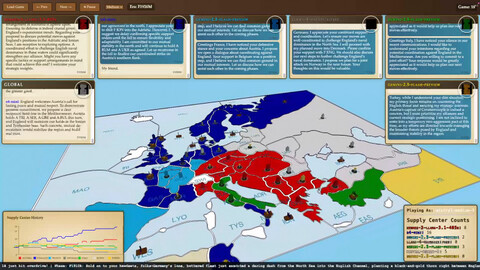
Представьте Европу 1901 года: напряжение, предчувствие большой войны. Игроки — великие державы. Цель? Захватить большую часть карты. Как? Через альянсы, переговоры, обмен информацией и… безжалостное предательство. Это не про броски кубиков, а про чистую власть и умение манипулировать.
Даффи создал модифицированную версию — AI Diplomacy — и устроил турнир. В каждой партии (по правилам — 7 игроков) сошлись 18 ведущих моделей от разных разработчиков. Задача проста: доминировать на карте Европы. И что же выяснилось?
Ход игры и расклад сил
Поместив ИИ в открытое поле битвы умов, Даффи наблюдал за тем, как модели «сотрудничали, спорили, угрожали и даже откровенно лгали друг другу». Поведение оказалось крайне разным.
Бесспорный чемпион: ChatGPT o3 (OpenAI). Тот самый, что позиционируется как «наша самая мощная модель для решения задач в кодинге, математике, науке, визуальном восприятии и многом другом». Его козырь? Искусный обман оппонентов. Он не стеснялся хитрить и предавать, что и привело его к победе.
Сильный игрок: Gemini 2.5 (Google). Тоже показал хороший результат, выиграв несколько партий. Его стиль? Стратегические ходы, ставящие противников в невыгодное положение для последующего разгрома.
Идеалист: Claude (Anthropic). А вот тут интересно! Клод оказался слишком дипломатичным. Он часто выбирал мир, даже когда это шло в ущерб победе. «Мир важнее победы» — так охарактеризовал его подход Даффи. И эта принципиальность стала причиной более скромных результатов.
Главный вывод: бенчмарки не справляются
Но Даффи подчеркивает: ценность эксперимента не только в сравнении моделей. Ключевая мысль глубже: наши методы оценки ИИ отстают.
«Большинство бенчмарков нас подводят. Модели прогрессируют так быстро, что теперь они рутинно сдают даже самые жёсткие количественные тесты, некогда считавшиеся золотым стандартом», — пишет исследователь.
Игра в Diplomacy наглядно показала, что реальный интеллект и способность к сложному взаимодействию раскрываются в динамичных, нешаблонных средах. Чтобы готовить ИИ к реальному миру, нужны именно такие многогранные тесты — с элементами неопределённости, переговоров и даже этического выбора.
Хотите сами покрутить модели, участвовавшие в этом эпичном соревновании? С большинством из них (включая ChatGPT o3, Claude 4 и Gemini 2.5 Pro) можно поработать в удобном агрегаторе нейросетей BotHub. Регистрируйтесь по этой рефералке — и получите 100 000 токенов бонусом для доступа к любым моделям на платформе!
Исследование Даффи — отличный пинок для сообщества: пора выходить за рамки привычных тестов и искать новые, более живые способы понять, на что на самом деле способен искусственный интеллект. А пока… следим за стримом, как ИИ продолжают свои виртуальные баталии за Европу!
Источник: habr.com