Все мы уже привыкли к тому, что большие языковые модели любят «галлюцинировать». Чтобы побороть это, придумали RAG (Retrieval-Augmented Generation) — подход, когда модель не выдумывает ответ, а ищет его в предоставленных документах. Проблема в том, что большинство RAG-систем довольно прямолинейны: нашли первый попавшийся релевантный кусок — вставили в ответ. В итоге получается рерайт статьи из Википедии, а не глубокий анализ.
И вот, Google выложили в опенсорс проект Gemini Fullstack LangGraph — по сути, готовый шаблон для создания AI-агента, который не просто ищет, а проводит целое мини-исследование с рефлексией и самокритикой. Давайте разберемся, что там под капотом.
Что нам предлагают: фуллстек-шаблон для Research-агента
На поверхности это довольно стандартный фуллстек-проект: фронтенд на React и бэкенд на Python с FastAPI. Но вся суть — в архитектуре бэкенда, построенного на LangGraph. Это не просто цепочка вызовов LLM, а сложный граф состояний, который превращает пассивный поиск информации в активный исследовательский процесс.
Скрытый текст
Frontend: React (с Vite), Tailwind CSS, Shadcn UI.
Backend: LangGraph, FastAPI, Google Gemini.
Production: Docker, Redis (для Pub/Sub и стриминга), PostgreSQL (для хранения состояний, тредов и очередей).
Проект не просто демка, а вполне себе production-ready шаблон, который можно взять за основу для собственного продукта. Но самое ценное здесь не код, а сам подход.
Главная фишка: цикл «поиск → рефлексия → уточнение»
В отличие от классического RAG, который работает по принципу «нашёл — ответил», этот агент действует как дотошный научный сотрудник. Весь процесс построен вокруг итеративного цикла:
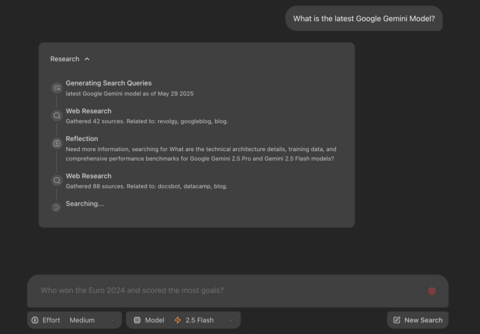
Генерация гипотез (поисковых запросов). Получив исходный вопрос от пользователя, агент с помощью Gemini формулирует несколько начальных поисковых запросов, чтобы охватить разные аспекты темы.
Сбор данных. С помощью Google Search API он собирает информацию по этим запросам.
Рефлексия и анализ пробелов. А вот тут и начинается магия. Агент не спешит генерировать ответ. Вместо этого он анализирует собранную информацию и задаёт себе критические вопросы: «Достаточно ли этих данных для полного ответа? Все ли термины раскрыты? Нет ли противоречий? Какую информацию ещё нужно найти?». Этот шаг — ключевой.
Итеративное уточнение. Если агент приходит к выводу, что данные неполны, он генерирует новые, более узкие и уточняющие запросы, чтобы закрыть выявленные «пробелы в знаниях». После этого он возвращается к шагу 2.
Синтез ответа. Цикл повторяется до тех пор, пока агент не решит, что собрал достаточно информации. Только после этого он приступает к генерации финального, развернутого ответа, подкрепляя его ссылками на все использованные источники.
Такой подход отличается от примитивного поиска по векторной базе.
Где ложка дёгтя?
Цена. Каждый шаг в этом цикле — это вызов Gemini. Итеративная рефлексия и генерация уточнений могут сделать итоговую стоимость одного ответа довольно высокой.
Скорость. Очевидно, что такой многоступенчатый процесс будет работать значительно медленнее, чем простой RAG. Для real-time чатов это может стать проблемой.
Сложность. Настроить и отладить такой сложный граф состояний — задача нетривиальная.
В итоге мы получаем классическую дилемму. Нужен ли такой уровень сложности для большинства задач? Кажется, для 90% типичных вопросов-ответов это явный оверинжиниринг. Но для тех 10% задач, где глубина и достоверность важнее скорости и цены, этот подход может оказаться хорош.
Источник: habr.com