Настольное приложение AnythingLLM, позволяющее локально использовать большие языковые модели (LLM) для конфиденциальной работы с искусственным интеллектом, теперь демонстрирует значительно более высокую производительность на ПК с видеокартами NVIDIA RTX благодаря интеграции микросервисов NVIDIA NIM.
Большие языковые модели (LLM), обученные на огромных объемах данных, генерируют высококачественный контент и являются основой для многих популярных ИИ-приложений. Один из самых доступных способов работы с LLM – это AnythingLLM, настольное приложение, созданное для энтузиастов, которые хотят иметь универсального помощника ИИ, ориентированного на конфиденциальность, непосредственно на своём ПК. Благодаря новой поддержке микросервисов NVIDIA NIM на графических процессорах NVIDIA GeForce RTX и NVIDIA RTX PRO, пользователи AnythingLLM теперь могут получить ещё более быструю производительность для более отзывчивых локальных рабочих процессов искусственного интеллекта.
Что такое AnythingLLM?
AnythingLLM – это универсальное ИИ-приложение, которое позволяет пользователям запускать локальные LLM, системы генерации с дополненным поиском (RAG) и агентные инструменты.
Оно действует как мост между LLM и данными пользователя, а также предоставляет доступ к «навыкам», что упрощает и повышает эффективность использования LLM для конкретных задач, в частности:
AnythingLLM может подключаться к широкому спектру локальных LLM с открытым исходным кодом, а также к более крупным облачным LLM (OpenAI, Microsoft, Anthropic). Приложение также предоставляет доступ к навыкам для расширения возможностей агентного ИИ через свой центр сообщества.
Благодаря установке одним щелчком мыши и интуитивно понятному интерфейсу, AnythingLLM является отличным вариантом для энтузиастов ИИ, особенно тех, кто имеет системы с графическими процессорами GeForce RTX и NVIDIA RTX PRO.
RTX обеспечивает ускорение AnythingLLM
Графические процессоры GeForce RTX и NVIDIA RTX PRO предлагают значительное повышение производительности для запуска LLM и агентов в AnythingLLM. Они ускоряют логический вывод благодаря тензорным ядрам, разработанным для ИИ.
1’>
AnythingLLM запускает LLM с Ollama для выполнения на устройстве, ускоренного благодаря тензорным библиотекам Llama.cpp и ggml. Ollama, Llama.cpp и GGML оптимизированы для графических процессоров NVIDIA RTX и тензорных ядер пятого поколения.
4
Например, производительность на GeForce RTX 5090 в 2,4 раза выше, чем у Apple M3 Ultra (на Llama 3.1 8B и DeepSeek R1 8B).
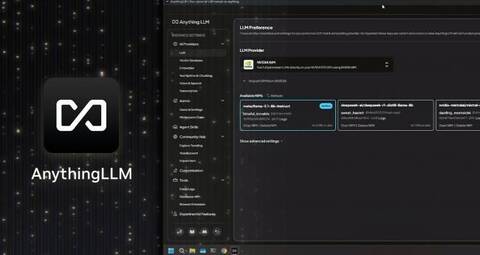
AnythingLLM — теперь с NVIDIA NIM
AnythingLLM недавно добавила поддержку микросервисов NVIDIA NIM — оптимизированных для производительности, предварительно упакованных генеративных моделей искусственного интеллекта, которые упрощают начало работы с ИИ на ПК с RTX AI через оптимизированный API.
NVIDIA NIM отлично подходят для разработчиков, которые ищут быстрый способ тестирования моделей генеративного ИИ. Вместо того чтобы искать нужную модель, загружать все файлы и решать, как всё подключить, NIM предоставляют единый контейнер, который содержит всё необходимое. Они могут работать как в облаке, так и на ПК, что упрощает создание прототипов локально, а затем развёртывание в облаке.
Предлагая NIM в удобном интерфейсе AnythingLLM, пользователи получают быстрый способ тестировать и экспериментировать с ними, а затем интегрировать их в свои рабочие процессы или использовать с чертежами NVIDIA AI, документацией и образцами кода NIM для непосредственного подключения к своим приложениям или проектам.
Павлик Александр
Источник: ru.gecid.com