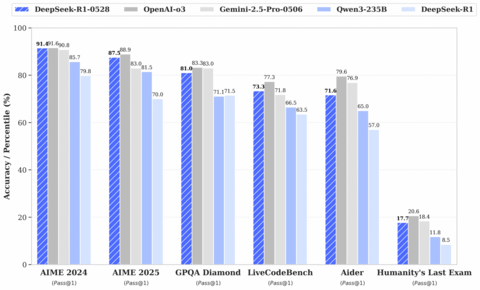
Обновленная версия R1-0528 показывает результаты лучше чем первая версия R1 во всех областях. Модель архитектурно не изменилась, улучшили только само обучение.
В LiveBench модель показывает не плохие результаты.
Кроме обновленной R1 представлена версия DeepSeek-R1-0528-Qwen3-8B. Эта дистиллят R1-0528 сделанный на модели Qwen3-8B.
Локальный запуск
gguf для локального запуска: https://huggingface.co/unsloth/DeepSeek-R1-0528-GGUF
1.78-битная версия требует 185гб + размер контекста. В новый версия llama.cpp и ik_llama доступно переопределение тензоров -ot или —override-tensor. Используется regexp для управления какие тензоры куда будут направлены. Например, команда:
-ot «.ffn_.*_exps.=CPU» -ngl 99
В этом случае MoE-веса, то есть веса отдельных экспертов, отправляются на CPU, а общие веса попадают на GPU. Таким способом одна GPU даст хорошее ускорение.
До этого, на GPU отправлялись только целые слои, то есть отдельные конкретные эксперты, так как DeepSeek это MoE модель, у которой только 37B весов активны на каждом шагу вычисления следующего токена. Из-за такого распределения, те слои, что попали на GPU будут выполнятся не каждый шаг, но если загрузить на GPU общие тензоры, которые нужны на каждом шагу, то это даст ускорение.
Если памяти не хватает, для запуска с ssd, можно попробовать добавить команду —ubatch-size 1- это позволит вычислялся pp батчами по 1, а не по 512, если ssd не достаточно производительный.
Попробовать онлайн
Бесплатный api и чат на openrouter:
https://openrouter.ai/deepseek/deepseek-r1-0528:free
https://openrouter.ai/deepseek/deepseek-r1-0528-qwen3-8b:free
На сайте https://chat.deepseek.com/ уже работает новая версия.
Источник: habr.com