В библиотеке Ollama, популярной платформы для локального запуска LLM, сегодня появились две новые модели: Mistral Small 3.1 и DeepCoder-14B-Preview.
Mistral Small 3.1 демонстрирует значительные улучшения в текстовой производительности, понимании мультимодальных данных и значительно расширенное окно контекста до 128 000 токенов. Модель превосходит сопоставимые модели, такие как Gemma 3 и GPT-4o Mini, при этом сохраняя впечатляющую скорость вывода в 150 токенов в секунду. Модель выпущена под лицензией Apache 2.0. И она работает на одной RTX 4090 или Mac с 32 ГБ оперативной памяти. https://ollama.com/library/mistral-small3.1
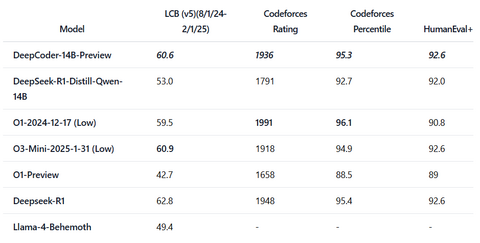
DeepCoder-14B-Preview зарекомендовала себя как ведущая модель для логического анализа кода. Обученная на основе Deepseek-R1-Distilled-Qwen-14B с использованием распределенного RL, она достигает впечатляющей точности 60,6% Pass@1 на LiveCodeBench – улучшение на 8% – сопоставимой с производительностью o3-mini-2025-01-031 (Low) и o1-2024-12-17, при этом используя всего 14 миллиардов параметров. https://ollama.com/library/deepcoder
Хотите попробовать эти модели, но не хватает ресурсов? Вы можете установить их в наш AI чат-бот, включая возможность почасовой аренды сервера. https://hostkey.ru/apps/machine-learning/ollama-ai-chatbot/
Источник: habr.com