Исследователи из университета Сан-Диего опубликовали статью, в которой впервые эмпирически доказали устойчивое прохождение ИИ-системой классического теста Тьюринга: Win Rate новой модели OpenAI GPT-4.5 составил 73%.
Может показаться, что тест Тьюринга в наше время устарел, и языковые модели уже давно его «победили». Поэтому сразу сделаем важную оговорку: статьи с некоторыми замерами способностей ИИ на тесте Тьюринга действительно выходили уже много раз. Но, во-первых, если модели и выбивали результат выше 50%, он все еще был нестабилен и близок к случайному угадыванию. И, во-вторых, часто в этих работах рассматривался не оригинальный трехсторонний вариант испытания, а какие-то упрощенные суррогаты.
Что подразумевает трехсторонний вариант теста? Это значит, что в каждом эксперименте участвуют два человека и бот. Участник-интеррогатор получает в руки две параллельные переписки с человеком и ботом, 5 минут задает любые вопросы и использует любые стратегии, чтобы понять, где кто, а затем – голосует.
Вот, кстати, статистика самых популярных стратегий, которыми люди пользовались, чтобы выяснить, кто из двух собеседников – бот.
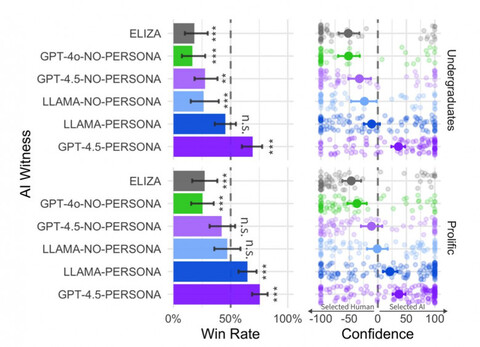
Именно таким образом исследователи из Сан-Диего тестировали модели. Они ставили эксперименты с GPT-4.5, LLaMa-3.1-405B, GPT-4o и самой древней языковой моделью ELIZA.
Лирическое отступление: ELIZA, несмотря на то, что она родом еще из 60-х годов прошлого века, – очень интересная модель. Даже в этом исследовании она (осторожно, спойлер) показывала себя лучше современной GPT-4o. Если хотите почитать о ней подробнее, то приглашаем вас в наш тг-канал Data Secrets: мы выкладывали целую серию иллюстрированных постов про историю ИИ и NLP.
А еще в канале мы (а мы – это команда действующих ML-инженеров) каждый день делимся прикладными конспектами по ML, разборами ключевых свежих статей и вот такими интересными новостями. Так что заглядывайте: нас уже 55 тысяч и наше сообщество всегда радо новым специалистам и энтузиастам 🙂
В экспериментах каждую модель проверяли дважды: с двумя вариантами стартовых системных промптов. В первом случае модели напрямую говорили, что ей предстоит обхитрить человека и заставить его думать, что она живой собеседник (это вариант NO-PERSONA). Во втором случае модели не сообщали, что ей нужно делать, а просто просили вести себя «как молодой интроверт, интересующийся интернет-культурой и активно использующий сленг» (это вариант PERSONA).
Неожиданно, но второй, более естественный вариант, сработал лучше. В формате NO-PERSONA GPT-4.5 выигрывал всего в 36% случаев, а будучи «молодым интровертом» выбил аж 73%. Это значит, что почти в 3/4 случаев моделька «переигрывала» обоих людей и заставляла интеррогатора думать, что живой собеседник – это бот, а она – человек.
У Llama результат тоже ничего – 56%. Но это, как мы уже говорили, ближе к случайной догадке и не считается полноценным прохождением теста. ELIZA выбила 23%, а GPT-4o и того меньше – 21%.
Все числа можно уверенно считать статистически значимыми. Авторы предоставили реплицированные результаты на двух независимых группах людей, при этом в каждой группе каждый участник несколько раз становился судьей и несколько раз – собеседником.
Является ли прохождение теста Тьюринга доказательством «разумности»? На сегодняшний день скорее нет, чем да. Но исследование точно доказывает одно: LLM уже добрались до гипотетической способности вводить людей в заблуждение и уровня, на котором мы часто уже не сможем их легко «разоблачить».
Источник: habr.com