Исследователи из Стэнфорда выпустили статью про то, как обучили модель играть в Among Us, при этом не используя вообще никаких размеченных людьми данных. Вместо этого они применяли только обучение с подкреплением и несколько этапов файнтюнинга, в ходе которых агенты учились общаться, убеждать, лгать или предсказывать предателя (импостера).
Поведение получившихся ИИ-игроков очень напоминает поведение человека: они манипулируют соперниками, врут (правда иногда без повода) и генерируют ложные обвинения. В полностью симуляционных играх их процент победы составляет 56%, а в играх против людей – примерно 45. Да, люди все еще сильнее, но учитывая, что игра требует от игроков сложной социальной стратегии, это удивительный результат. Поехали разбираться, как ученые этого добились.
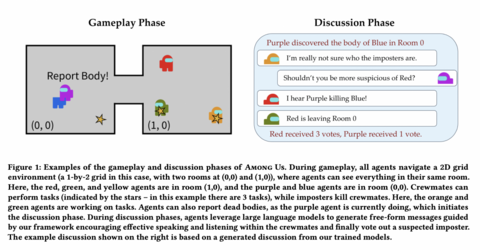
Пример игрового процесса и обсуждения в Among Us. Агенты перемещаются по сетке 1×2 с двумя комнатами, и видят всё в пределах своей комнаты. Члены экипажа (красный, зелёный, жёлтый) выполняют задания (отмечены звёздами), а импостеры убивают экипаж. Фиолетовый агент нашёл тело и сообщил о нём, запустив фазу обсуждения: в ходе нее агенты обмениваются сообщениями и голосуют за подозреваемого.
Итак, на первом этапе агенты должны понять общие правила игры и научиться действовать внутри игровой среды. Для того, чтобы обучить их этому, использовалось обучение с подкреплением, а именно классический алгоритм PPO. Если кратко, на каждом шаге алгоритма у агента есть начальная политика, на основе которой он совершает какие-то действия и получает оценку этих действий от среды. На основе таких оценок агент корректирует свою политику, с которой переходит на следующую итерацию, а затем все повторяется.
Дисклеймер: здесь мы привели лишь краткое поверхностное описание алгоритма. На самом деле PPO гораздо интереснее и глубже, как и другие методы обучения с подкреплением.
Если вас интересуют детали, то вот здесь в нашем тг-канале Data Secrets мы делали большой схематичный разбор PPO и его вариации – GRPO, которая лежит в основе DeepSeek-R1. Кстати, мы – это команда действующих ML-инженеров, и в телеграме мы ежедневно делимся своими конспектами по ML и вот такими разборами свежих статей. Так что заглядывайте: мы и наше большое сообщество всегда радо новым специалистам и энтузиастам 🙂
В этом случае для агента игра формулировалась как частично наблюдаемая марковская. Это значит, что каждое состояние игры представляется как скрытая переменная, и у агентов есть ограниченные наблюдения. Кроме того, исследователи добавили сюда компоненту социального дедуктивного анализа: то есть агентам нужно не только взаимодействовать с окружающей средой, но и делать выводы на основе обсуждений. Все как у людей.
И да, обучение с подкреплением работает хорошо, но тут его оказывается недостаточно. Агенты действительно хорошо выучивают общие правила и свойства среды, но плохо обучаются общению. Дело в том, что награды за победу слишком редкие и не дают точного сигнала о качестве дискуссии. А ведь в этой игре важно именно общение и построение стратегии.
Так что следующим этапом идет улучшение способностей слушания. Идея в том, что модель обучают извлекать из диалогов полезную информацию: такую, которая помогает делать общие выводы внутри игры. А внутри Among Us главный вывод – это вывод о том, кто из игроков – импостер, так что успех модели на этом этапе определялся просто точностью ее детекции предателя.
Listening loss. Функция потерь, с помощью которой определяется успех агента. Здесь q — истинный импостер, а тетта – предсказания модели на основе истории игры.
Но и это не все. Ведь чтобы донести свои верные предсказания до соратников, модель еще должна научиться убедительно разговаривать. Поэтому следующим этапом обучения стало улучшение «говорения», и оценивали его через степень влияния на других агентов. Функцией потерь стало буквально то, что сообщение данного агента изменило мнение других агентов в правильном направлении.
Функция потерь для этапа говорения. Bt — суммарная уверенность всех агентов в том, кто является импостером.
Кстати, похожим образом обучали и самих импостеров. Правда вместо того, чтобы убеждать других агентов в правильной позиции, они, напротив, пытались их дезинформировать.
С помощью трех описанных этапов обучение зацикливалось. Это называется self-play: модели обучаются друг против друга, постепенно улучшая свою стратегию. Кстати, надо сказать, что внутри архитектуры не обычный трансформер, как мы привыкли, а RWKV – рекуррентная модель с линейным вниманием. Ее выбрали, потому что она лучше масштабируется на большой контекст, а в этой задаче это незаменимо. Из трансформера здесь позаимствованы ключи и значения (Key Value), но никакого скалярного произведения между ними нет. Вместо этого в сеть добавляются тензоры Receptance и Weight – аналоги скрытого состояния и гейта забывания из RNN, которые как бы занимают место слоев внимания.
В итоге эксперименты показали, что обученные таким образом модели (RL + listening + speaking), выигрывают в 2 раза чаще, чем стандартные агенты RL. Вот иллюстрация:
Видно, что лучше всего улучшает метрику обучение слушанию. Причем модель, обученная только слушанию, работает даже лучше, чем модель, обученная только с помощью обучения с подкреплением.
Можно заметить, что добавление компонента «говорения» не приводит к сильному росту метрик, в отличие от «слушания». Зато именно благодаря ему у агентов появляются эмергентные стратегии, такие как прямые обвинения и ложные обвинения.
В случае игры с людьми агенты выигрывают в 45% случаев. То есть люди пока побеждают, но разрыв значительно уменьшился. Для сравнения, базовая модель выигрывает только в 15-20% случаев. В основном живые игроки выигрывают за счет того, что лучше распознают ложь: агенты часто верят в подозрения кого-то со стороны других, но не умеют проверять их. Кроме того, люди могут намеренно создавать хаос, а агенты пока не умеют провоцировать друг друга и часто сыпятся на прямых обвинениях или неуместных фразах.
Самое главное в этой работе – это пожалуй то, что обучение происходило вообще без использования разметки от человека. Это в который раз доказывает, что языковые модели могут научиться играть в социальные дедуктивные игры, участвовать в обсуждениях и даже влиять на решения других — и все это только на основе самообучения. Так и до жизни в обществе недалеко 🙂
Полный текст статьи вы можете найти здесь, а вот тут лежит весь код и демо.
Источник: habr.com