Разработчики представили библиотеку Llama OCR, предназначенную для распознавания изображений с помощью нейросети Llama Vision. Библиотека написана на языке TypeScript и рассчитана на использование в веб-приложениях.
Llama OCR использует бесплатные конечные точки API от Together AI для доступа к нейросети. Это позволяет отправлять запросы в виде изображений и получать распознанные символы в формате Markdown. Также доступны и платные конечные точки для моделей Llama 3.2 11B и Llama 3.2 90B. Они могут пригодиться для масштабных проектов с большим количеством пользователей, в которых важна скорость.
Выбрать модель можно с помощью параметра model. Доступны опции free, Llama-3.2-11B-Vision и Llama-3.2-90B-Vision. По умолчанию выбрана последняя опция. Также разработчики отмечают, что сейчас доступно распознавание текста на изображениях, но в ближайшее время добавят возможность работать с PDF-документами.
Установить библиотек можно с помощью пакетного менеджера npm:
npm i llama-ocr
Пример использования в коде выглядит следующим образом:
import { ocr } from «llama-ocr»; const markdown = await ocr({ filePath: «./trader-joes-receipt.jpg», // path to your image (soon PDF!) apiKey: process.env.TOGETHER_API_KEY, // Together AI API key });
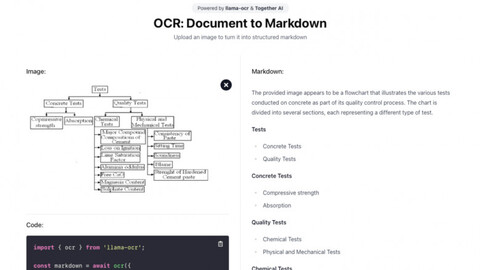
Разработчики развернули тестовое веб-приложение, которое распознаёт англоязычный текст на изображениях. Если отправить фотографию с русскоязычным текстом, то ответ всё равно будет на английском.
Источник: habr.com