Исследователи из Transluce – только что анонсированной некоммерческой ИИ лаборатории – создали инструмент Monitor, который поможет людям наблюдать, понимать и управлять внутренними вычислениями языковых моделей. В ходе экспериментов ученые рассмотрели несколько известных задач, в которых LLM традиционно ошибаются, и выяснили, с чем могут быть связаны такие галлюцинации.
LLM – черный ящик. Мы можем наблюдать только входы и выходы модели, но отследить ее «мысли», то есть проанализировать глубокие процессы активации миллиардов нейронов – довольно нетривиальная задача. Над этой проблемой в последнее время активно работают многие ML-исследователи: статьи на тему интерпретируемости выходят чуть ли не каждую неделю. Мы часто пишем о них в нашем тг-канале Data Secrets: вот, например, разбор статьи от Anthropic про то, почему все-таки так сложно понимать нейросети, вот обзор метода интерпретации «мыслей» LLM от Ильи Суцкевера и OpenAI, а вот – большой карточный пост про то, как думает Claude 3 Sonnet. В общем, если хотите быть в тренде ИИ-ресерча и индустрии – welcome!
Monitor – это еще одна попытка научиться понимать, как большие языковые модели обдумывают свои ответы. Как и предыдущие решения от OpenAI и Anthropic, инструмент основан на архитектуре SAE, то есть на разреженных автоенкодерах, которые распутывают активации LLM и достают из них так называемые интерпретируемые «фичи» (подробнее про то, как устроены такие автоенкодеры, – здесь). Фичи можно воспринимать, как темы, концепции или кластеры. В интерфейсе Monitor можно в реальном времени наблюдать, нейроны каких групп активируются при ответе на конкретный вопрос сильнее всего.
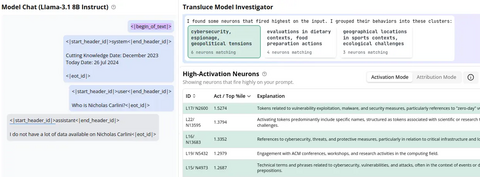
Подобные инструменты нужны не только для того, чтобы просто отслеживать мысли LLM, но и чтобы отлавливать ошибки, понимать причины галлюцинаций и исправлять их. В частности есть несколько задач, на которых по каким-то причинам ошибаются большинство моделей. Например, известная проблема сравнения чисел 9.8 и 9.11 – модели почему-то традиционно считают, что 9.11 больше. При этом версия о том, что дело в количестве знаков после запятой, неверна: в других аналогичных случаях модели ошибаются меньше.
Так в чем же дело? На скрине ниже видно, что модель (в данном случае Llama-3.1), когда пытается сравнить числа 9.8 и 9.11, активирует несколько неожиданных кластеров: например, всплывает информация про атаку 11 сентября (9.11) и гравитационную константу (9.8). Вероятно из-за того, что эти темы появлялись в обучающих данных Llama очень часто, числа 9.8 и 9.11 перестают восприниматься ею как обычные числа: она воспринимает их, как другой вид объектов (даты, константы), путается и несет чепуху.
Но это не все: мы можем погрузиться глубже и спросить у интерпретатора не просто о том, какие темы вообще активируются при ответе на вопрос, но и о том, какие именно из них заставляют модель сказать «больше». Если это проделать, то получается, что помимо двух уже рассмотренных кластеров модель почему-то начинает думать про Библию. Оказывается, определенные нейроны в этом кластере связаны со стихами из Библии, что также может вызвать проблемы, если 9.8 и 9.11 интерпретируются как 9:8 и 9:11 (глава: стих). Это неудивительно: большинство наборов данных для претрейна содержат много копий Библии.
Ученые предположили, что если избавиться от таких тематик, ведущих модель по неверному пути, она все-таки может дать верный ответ. И это заработало! Если с помощью интерпретатора «выключить» вышеперечисленные кластеры нейронов, то модель меняет свое мнение и отвечает правильно: 9.11 меньше 9.8.
Как видите, интерпретационные инструменты, такие как Monitor, действительно могут быть не просто интересными для исследователей, но и полезными для реальных ИИ-систем. Исследователи отмечают, что их тул – только прототип для видов интерфейсов с еще более широкими возможностями. Monitor в его нынешнем виде оставляет построение гипотез пользователю: он позволяет наблюдать, какие идеи лежат в основе вычислений модели, но не объясняет, как модели принимают окончательные решения с помощью этих идей. Агенты-исследователи будущего смогут это исправить и будут способны не только анализировать решения модели, но и помогать автоматически исправлять галлюцинации LLM.
Больше новостей, разборов статей про ИИ, интересных проектов и ML-мемов в нашем тг‑канале. Подпишитесь, чтобы ничего не пропустить!
Источник: habr.com