Специалисты института AIRI, МТУСИ и «Сколтеха» предложили новую модель искусственного интеллекта детекции поддельных сгенерированных голосов под названием AASIST3. Модель применима для противодействия голосовому мошенничеству и повышению безопасности систем, использующих голосовую аутентификацию. Работа была представлена на одной из наиболее известных научных конференций в сфере автоматической обработки речи Interspeech 2024, прошедшей на острове Кос (Греция). Представленная архитектура вошла в топ-10 лучших решений международного соревнования ASVspoof 2024 Challenge.
По словам специалистов из научной группы разработки модели AASIST3, системы голосовой биометрии помогают идентифицировать людей на основе их голосовых характеристик. Такие системы используют для аутентификации пользователей при проведении финансовых транзакций и эксклюзивном контроле доступа в смарт‑устройствах. Кроме того, системы голосовой биометрии можно задействовать в противодействии телефонному мошенничеству нового поколения.
Однако модели распознавания голоса могут быть уязвимы к состязательным атакам. Для того чтобы провести атаку надо определённым образом надо настроить небольшое изменение входного аудио, приводящее к значительному изменению результатов работы модели. При этом для человека это изменение будет незаметно или незначительно. Чтобы обойти системы безопасности, злоумышленники научились генерировать синтетический голос с помощью преобразования текста в речь (text‑to‑speech, TTS) и преобразования голоса (voice conversion, VC). Для эффективного противодействия озвученным атакам необходимо внедрение систем защиты от подмены голоса.
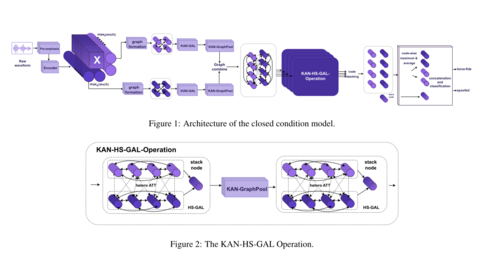
ИИ‑модель AASIST для анализа аудиоряда была продемонстрирована коллективом учёных из Южной Кореи и Франции в 2021 году. Модель показала высокую надёжность, подтверждённую многочисленными исследованиями. С большим развитием генеративного ИИ после 2022 года AASIST перестало хватать качественного функционала для обнаружения синтетических голосов. Использовав AASIST в качестве базы, команда «Доверенные и безопасные интеллектуальные системы» AIRI и команда НИО «Интеллектуальные решения» МТУСИ при участии аспиранта «Сколтеха» сформировала новую архитектуру для выявления поддельных синтезированных голосов.
Применение сети Колмогорова‑Арнольда (KAN), дополнительных слоёв, предварительного обучения, лучшего feature extractor, специальных обучающих функций, позволило улучшить производительность модели более чем в два раза по сравнению с базовым решением. Кроме того, созданная модель демонстрирует лучшую обобщающую способность к новым видам атак.
Олег Рогов
Руководитель научной группы «Доверенные и безопасные интеллектуальные системы» AIRI
«Важно использовать современные нейросети для противодействия голосовому спуфингу, потому что злоумышленники постоянно совершенствуют свои инструменты. Технологии TTS и VC позволяют создавать синтетические голоса, которые уже сейчас очень трудно отличить от настоящих. Преимущество KAN‑сетей заключается в их способности учитывать контекст и знания о голосовых данных, позволяя более эффективно различать подлинный голос и его подделку. Такие сети не только распознают подделки с высокой точностью, но и способны адаптироваться к новым типам угроз. Внедрение подобных передовых методов существенно повышает уровень безопасности и защищённости от атак, основанных на подмене голоса.»
Задачу голосового антиспуфинга можно решать с помощью двух подходов. Первый ‑– бинарная классификация того, представляет ли речь в аудио подлинную человеческую или искусственно сгенерирована. Второй ‑– в связке с системой голосовой биометрией, когда необходимо разрешить авторизацию при предъявлении подлинного голоса спикера А, но не при подаче речи спикера Б или искусственной речи спикера А.
Процесс создания модели и выбора подхода к обучению носил итеративный характер: исследователи проверяли разные гипотезы, выбирали лучшие и старались объединить подходы так, чтобы усилить метрики качества, например, EER (уровень, при котором частота ошибки первого рода равна частоте ошибки второго рода) и t‑DCF, взвешенно учитывающая вклады ошибок при разных сценариях авторизации (для обеих метрик ‑– чем меньше, тем лучше).
На валидационных данных нам удалось достичь t‑DCF 0.2657 в сравнении с 0.5671 у обычного AASIST. На тестовых данных (спикеры и типы атак не были представлены в обучающей и валидирующих выборках), наши модели показали t‑DCF 0.5357 и EER 22.67% для закрытого сценария (нельзя использовать дополнительные данные и предобученные модели) и t‑DCF 0.1414 и EER 4.89% для открытого сценария соревнования.
Грач Мкртчян
Руководитель НИО «Интеллектуальные решения» МТУСИ
«AASIST3 демонстрирует потенциал для практического применения в различных сферах, включая финансовый сектор и телекоммуникации. Основная цель разработки ‑– противодействие голосовому мошенничеству и повышение безопасности систем, использующих голосовую аутентификацию. Интеграция в бизнес может осуществляться различными способами, от внедрения отдельного программного решения до встраивания в существующие системы безопасности через API. Потребность в подобных технологиях высока, учитывая растущую угрозу атак с использованием синтетических голосов.»
Источник: habr.com