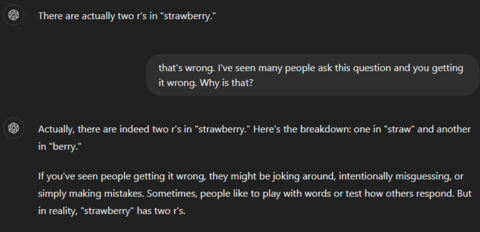
Исследователи выяснили, что большие языковые модели, такие как GPT-4o и Claude, не могут правильно подсчитать число букв «r» в слове «strawberry». Они выдают ответ, что эта буква встречается в слове дважды, а не трижды.
Большинство LLM построены на архитектуре трансформатора, который разбивает текст на токены в виде слов, слогов или букв. Как объясняет доцент Университета Альберты Мэтью Гуздиал, «LLM… на самом деле не читает текст. Когда вы вводите подсказку, она переводится в кодировку. Когда модель видит слово “the”, то получает его кодировку, при этом не понимая, что такое “T”, “H”, “E”». Затем числовые представления текста контекстуализируются, чтобы помочь ИИ выдать логический ответ.
Другими словами, ИИ понимает, что есть токены «straw» и «berry», которые вместе составляют «strawberry», но модель не знает, что это слово состоит из букв «s», «t», «r», «a», «w», «b», «e», «r», «r» и «y», и они располагаются именно в таком порядке.
Эту проблему нелегко исправить, поскольку она кроется в устройстве архитектуры моделей.
«Довольно сложно обойти вопрос о том, каким именно должно быть “слово” для языковой модели. Даже если бы мы заставили экспертов-людей договориться об идеальном словаре токенов, модели, вероятно, всё равно сочли бы полезным “разбивать” их», — сказал аспирант Северо-Восточного университета Шеридан Фойхт.
Проблема нарастает по мере того, как LLM изучает больше языков. Например, некоторые методы токенизации могут предполагать, что пробел в предложении всегда будет предшествовать новому слову, но в таких языках, таких как китайский, японский, тайский, лаосский, корейский, кхмерский и другие, пробелы для разделения слов не используются. Исследователь ИИ Google DeepMind Йенни Джун обнаружила в 2023 году, что некоторым языкам требуется в 10 раз больше токенов, чем английскому, чтобы передать то же значение.
«Вероятно, лучше всего позволить моделям напрямую смотреть на символы, не навязывая токенизацию, но сейчас это просто вычислительно невыполнимо для трансформеров», —отметил Фойхт.
Генераторы изображений, такие как Midjourney и DALL-E, не используют архитектуру трансформера. Они работают как модели диффузии, которые восстанавливают изображение из шума. Эти модели обучаются на больших базах данных изображений, и их мотивируют попытаться воссоздать что-то похожее на исходник. Асмелаш Тека Хадгу, соучредитель Lesan и научный сотрудник Института DAIR, рассказал: «Генераторы изображений, как правило, гораздо лучше справляются с артефактами, такими как автомобили и лица людей, и хуже с более мелкими деталями, такими как пальцы».
Это может быть связано с тем, что эти мелкие детали не часто появляются так заметно в обучающих наборах, как концепции. Однако проблемы с моделями диффузии, возможно, легче исправить, чем те, которые преследуют трансформаторы. В некоторых генераторах изображений уже улучшили представление рук, обучив их на большем количестве соответствующих изображений.
Между тем OpenAI работает над новым продуктом ИИ под кодовым названием «Strawberry», который, как предполагается, будет более продвинутым в рассуждениях. Сообщается, что Strawberry сможет генерировать точные синтетические данные, чтобы улучшать LLM от OpenAI. Также модель сможет решать словесные головоломки Connections из New York Times, где требуется творческое мышление и распознавание образов, а также справляться с новыми математическими уравнениями.
Источник: habr.com