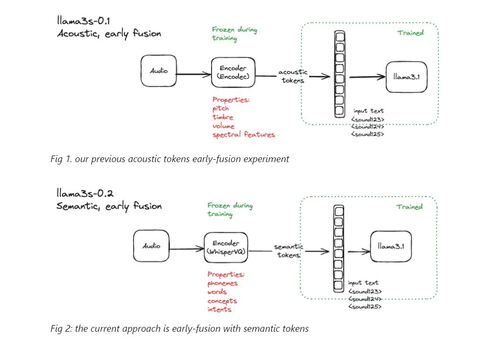
Разработчики Llama3-s v0.2 поделились улучшениями, которые модель продемонстрировала в тестах понимания речи и способности «слушать». В llama3-s v0.1 начали внедрять акустические токены. В v0.2 реализовали слияние с семантическими токенами, которые обладают такими преимуществами, как простота, лучшее сжатие и последовательное извлечение признаков речи.
Сначала модель прошла предварительное обучение на примерах реальной речи с помощью экспериментов с грубой абляцией. Это повысило способность llama3 обобщать семантические токены.
Затем был использован набор данных MLS-10k, который включает 10 часов немаркированной многоязычной человеческой речи. С помощью него llama3.1 8b обучили предсказывать следующий токен в последовательности.
Предварительное обучение включало 5 тысяч шагов и заняло более 30 часов. Разработчики использовали полностью сегментированные параллели данных Torchtune, оптимизатор AdamW Fused, а также следующие параметры:
После 5 тысяч шагов потери сходились на уровне чуть ниже 2, после чего разработчики перешли на следующий этап.
Для обучения использовали один узел 10x RTX A6000.
Для второго этапа обучения llama3 настраивали с помощью чередования синтетических данных. Для этого был использован синтетически сгенерированный набор речевых данных, которые семантически кодировались с помощью WhisperVQ из WhisperSpeech. Набор включал 70% подсказок для речевых инструкций и 30% подсказок для транскрипции.
Настройку выполнения инструкций выполняли с помощью оптимизатора AdamW Fused и планировщика обучения Cosine. Этот этап занял 32 часа и включал 7261 шаг. Его проводили с применением Nvidia H100.
Оба этапа обучения обошлись менее чем в $600, а весь эксперимент стоил менее $2800, учитывая неудачные запуски из-за ошибок и сбоев инфраструктуры.
В тесте AudioBench для оценки больших языковых моделей аудио (AudioLLM), который измеряет речевые возможности, llama3-s v.02 достигла среднего балла 3,53 в оценке ALPACA-Audio.
Модель всё ещё находится на ранней стадии разработки и чувствительна к плохому сжатию входящего звука, не может слушать аудио длительностью более 10 с, пока не обучена на шуме.
Источник: habr.com