В начале августа организация OpenAI представила улучшенные функции структурирования ответов своих больших языковых моделей. Обещалось, что теперь модели будут точнее следовать формату JSON в ответах. Проект Aider сравнил качество кода в различных форматах ответов и пришёл к выводу, что любые БЯМ пишут код лучше, если отвечать нужно в plain text.
В начале августа реддитор нашёл в недрах бета-версии операционной системы macOS 15.1 текст, похожий на системные промпты функции Apple Intelligence. Речь идёт про показанную на конференции разработчиков WWDC этого 2024 года концепцию искусственного интеллекта. ИИ от Apple должен быть тесно интегрирован в операционную систему и помогать в повседневных задачах: предлагать варианты ответа на электронные письма, сжато описывать переписку в мессенджерах и самостоятельно монтировать фотографии в памятный видеоролик.
Промпты — написанные естественным языком сообщения для модели, в данном случае большой языковой (БЯМ). В обсуждениях находки на Reddit и в микроблогах (1, 2, 3) стиль промптинга Apple вызывал нарекания. Чаще всего критикам казались забавным фразы по типу «не галлюцинируй» и ненужная вежливость «пожалуйста». Немногие высказались, что просьба возвращать валидный JSON приведёт к багам и иногда сломанному форматированию.
Для обработки некоторых запросов Apple Intelligence работает в тесном сотрудничестве с OpenAI. Ещё в ноябре 2023 года на DevDay организация OpenAI представила режим JSON Mode, который помогает модели возвращать правильный формат JSON.
6 августа, уже после находок внутри бета-версии macOS, организация OpenAI объявила о новой функции ответов через API: Structured Outputs. Это дальнейшее развитие JSON Mode. Структурированные ответы помогают задать JSON Schema, чтобы БЯМ возвращала ответ в строго заданном формате.
OpenAI
В блоге OpenAI похвастала, что модель gpt-4o-2024-08-06 с параметром strict=true достигла уровень соответствия формату в 100 %. Для сравнения: через просто промптинг получалось добиться от gpt-4-0613 показателя в лишь 35,9 %. О реальном опыте клиентов объявление OpenAI ничего не сообщает.
Инструмент Aider — это бесплатный (доступ к API провайдера БЯМ придётся обеспечить самостоятельно) ассистент для написания кода прямо в терминале. Как рассказывает проект, часто пользователи удивлённо спрашивают: почему запросы на редактирование кода ассистент отсылает в виде простого текста?
К примеру, запрос от Aider на редактирование кода может выглядеть так:
greeting.py <<<<<<>>>>>> REPLACE
Как указывают авторы Aider, вопрошающие почему-то ожидают, что лучше было бы обернуть запрос в JSON:
{ «filename»: «greeting.py», «search»: «def greeting():n print(«Hello»)n» «replace»: «def greeting():n print(«Goodbye»)n» }
Чтобы объяснить свой выбор, проект Aider показывает результаты тестирования и наглядно доказывает, что БЯМ генерируют код хуже, если просить форматировать его в структуре JSON. Также указывается, что ничего удивительного в этом факте и не должно быть. В примере с JSON выше в код примешаны кавычки » и переносы строк n с экранированием. Легко представить, что это добавляет сложности генерации. Aider спрашивает: а насколько тяжело было бы писать такой код человеку?
Тесты со схожими выводами проект Aider уже публиковал в июле 2023 года. На тот момент рассматривать приходилось модели GPT-3.5 и GPT-4. Индустрия давно ушла вперёд, GPT-3.5 уже даже успели закрыть.
Тесты прогоняли на собственном бенчмарке Aider, состоящем из 133 задач по написанию кода на Python из репозитория Exercism. Задачи предназначены не для машин, а для помощи в изучении Python человеку. Каждая задача включает файлы, где отдельно лежат инструкции, заготовка кода с описанием требуемой функции или класса и юнит-тесты. От БЯМ требуется прочитать инструкции, написать код и пройти юнит-тесты.
В тестировании июля 2023 года при возникновении ошибок БЯМ получала результаты юнит-тестов, указание, что тестам нужно верить и что код нужно исправить. Для нового сравнения запросов в plain text и в структуре JSON бенчмарк слегка упростили. В частности, БЯМ давалась всего одна попытка без вторых шансов на исправления ошибок.
Рассмотрено было три стратегии оборачивания кода:
Markdown. Языковая модель выдавала нужный код в стандартной для этого языка разметки нотации, заключая его между блоками с тремя обратными апострофами «`. Этот вариант схож с тем, что используется для такого формата ответов, который в проекте Aider называется whole:
«` Here is the program you asked for which prints «Hello»: greeting.py def greeting(): print(«Hello») «`
JSON. С помощью вызова функции (function call) БЯМ заставляли отвечать в виде структурированного JSON. Ответ мог выглядеть так:
{ «explanation»: «Here is the program you asked for which prints «Hello»», «content»: «def greeting():n print(«Hello»)n» }
JSON (strict). То же, что и в предыдущем случае, но с указанием параметра strict=True. Это поддерживает только gpt-4o-2024-08-06.
Сравнению подвергли 4 модели:
claude-3-5-sonnet-20240620;
deepseek-coder-v2-0724;
gpt-4o-2024-05-13;
gpt-4o-2024-08-06.
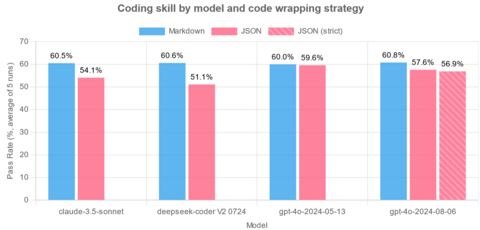
Каждую комбинацию модели и стратегии представления ответов БЯМ испытали 5 раз на каждой из 133 задач. Результат по 5 попыткам усреднили.
Aider
Все четыре модели показали более низкую производительность, когда их просили возвращать ответ в виде JSON. Aider также приводит другие любопытные наблюдения:
Больше всего от переключения на JSON пострадало качество ответов у claude-3-5-sonnet-20240620 и deepseek-coder-v2-0724.
gpt-4o-2024-05-13 оказалась единственной моделью, которая примерно одинаково хорошо отвечала как в Markdown, так и в JSON. Однако и здесь средний результат упал на 0,4 %.
Новый режим strict=True никак не повлиял на производительность. gpt-4o-2024-08-06 отвечала так же плохо, как и без него.
В некоторых случаях БЯМ допускают больше синтаксических ошибок в самом коде, если его нужно обернуть в JSON. Сам JSON будет валидным, просто отдаваемый внутри код будет содержать больше синтаксических ошибок.
Приводится статистика числа синтаксических ошибок. Здесь число ошибок суммируется по всем 5 попыткам и 133 задачам.
Aider
Заметно, что БЯМ компании Anthropic синтаксических ошибок в коде не допускала вне зависимости от формата представления ответа. Однако из предыдущих результатов заметно, что правильность от переключения на JSON всё равно заметно пострадала. На основе этого пост в блоге Aider приходит к выводу, что оборачивание в JSON может негативно влиять на способность к решению задач по написанию кода.
Проект Aider даже разбирает пример одной из ошибок синтаксиса кода. Следующую ошибку допустила gpt-4o-2024-05-13, когда ей нужно было отвечать в JSON. Вероятно, что БЯМ при оформлении структуры JSON запуталась в экранировании и цитировании.
Traceback (most recent call last): … File «bottle-song/bottle_song.py», line 9 lyrics.append(f’There’ll be {i — 1} green bottles hanging on the wall.’) ^ SyntaxError: unterminated string literal (detected at line 9)
Одинарная кавычка в There’ll экранируется в коде в There’ll, но также нужно второе экранирование для формата JSON (There\’ll). В итоге фрагмент правильного ответа от БЯМ выглядел бы так:
…lyrics.append(f’There\’ll be {i — 1} green bottles hanging on the wall.’)n…
Пост в блоге Aider приходит к выводу, что на данном этапе развития больших языковых моделей переключаться из plain text на форматирование ответов в JSON преждевременно.
Следует также отметить, что все представленные результаты нельзя сравнивать с рейтингом БЯМ от Aider — методы бенчмарка в данном случае заметно изменили для конкретной задачи сравнения моделей.
Источник: habr.com