Команда исследователей Google DeepMind выпустила датасет YouTube-SL-25, включающий более 3,2 часов видео на языке жестов. Данные охватывают более 25 языков мира.
Датасет собирали в несколько этапов. Сперва исследователи с помощью автоматического классификатора отобрали подходящие ролики с YouTube. После этого видео вручную отсортировали, выбрав наиболее качественные. Таким образом удалось отобрать более 81 тыс. видео. На последнем этапе количество роликов сократили до 39 тыс. общей длительностью более 3,2 тыс. часов. Для датасета подготовили подробные аннотации.
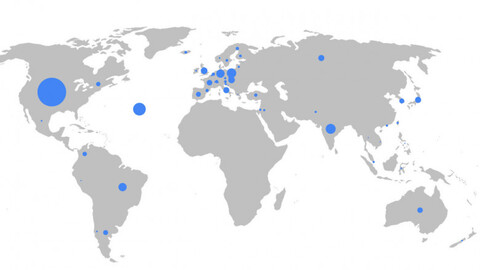
География сбора данных для YouTube-SL-25
Набор данных можно использовать для обучения моделей, предназначенных для распознавания жестов и автоматического сурдоперевода. До сих пор разработка нейросетей под эти задачи остаётся сложной для исследователей из-за нехватки открытых данных. У Google в коллекции есть датасет YouTube-ASL. Его проблема в том, что данные актуальны только для американского языка жестов, а общая продолжительность видео составляет менее 15 часов.
Датасет YouTube-SL-25 поддерживает более 25 языков. Больше всего данных доступно для амслена (американский жестовый язык) — 1394 часов контента. Для русского языка в наборе данных есть 60 часов видео. Меньше всего доступно для датского, эстонского и швейцарского диалекта итальянского — по часу контента на каждый.
Доступные языки
Команда Google DeepMind опубликовала подробности создания датасета YouTube-SL-25, а идентификаторы видео из набора доступны на платформе Google Cloud.
Источник: habr.com